
Autoresearch &
test-time compute for
information retrieval


dataroom: a loop for knowledge dump.
Given a token budget, spend it on local small models instead of a frontier model: run search → read → write, repeat, until the knowledge is dumped into one cited .zip. That dump is the dataroom - the open web distilled down to a small, local corpus a machine can consume.
Stage one of two: the grounded .zip then goes to searchbox (next) or a frontier model for the expensive second stage.


searchbox: a testbed for studying agentic search loops.
An airgapped testbed for search as test-time compute: lock an agent in the box with one .zip dataroom and no web, so it can only answer by composing its own pipeline from local tools - grep, embed, rerank, similarity, cluster, select_diverse. Nothing leaks in; the search has to exhaust what is in the box.
Which tool does the agent reach for first?
Is grep all you need: where does a dense retriever add nothing?
Does forcing more token budget (scaling TTC) help on the hard questions?
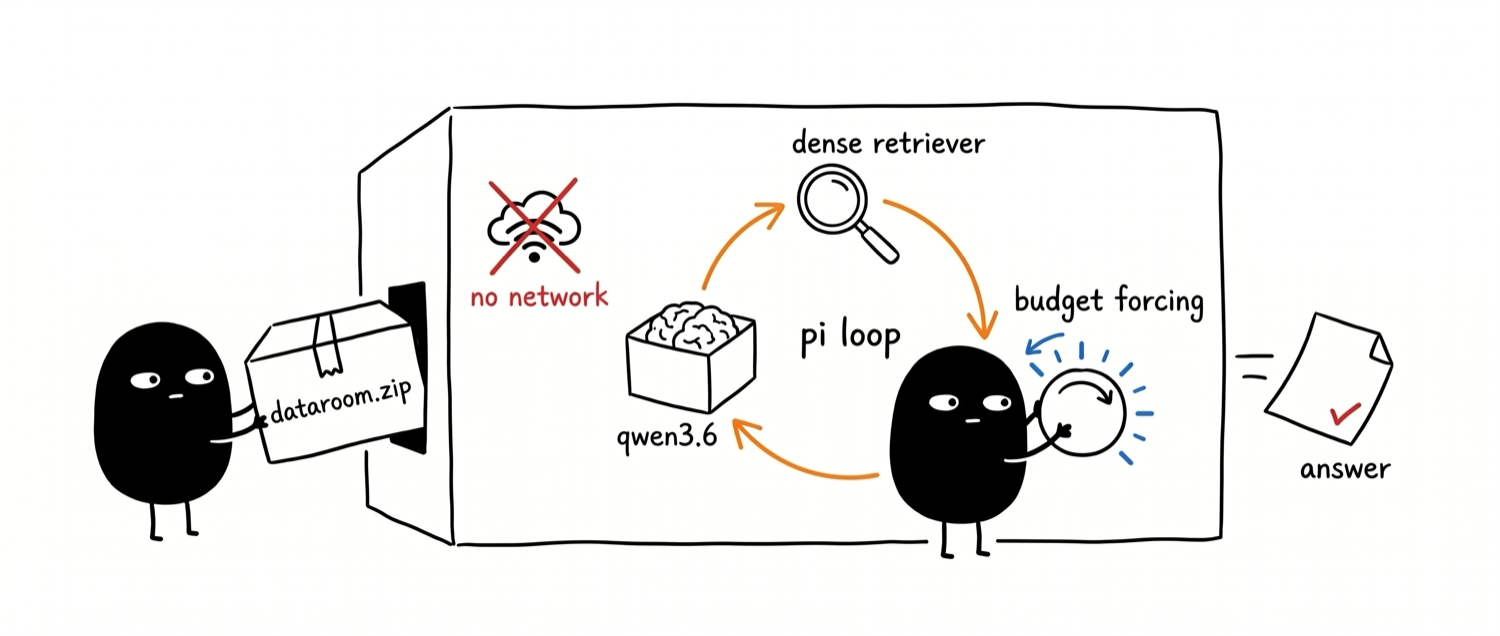

knowledge-graph: hard multi-hop questions for a private verifier.
Trivial questions are useless for agentic search: if one grep finds the answer, every method scores the same. To evaluate searchbox you need questions that force the search to actually work.
Turn the corpus into a knowledge graph - each fact a (subject)-[predicate]->(object) edge - then walk its longest paths. Those chains become hard multi-hop questions no single passage answers: a private, corpus-grounded eval, grown from the same corpus searchbox is locked inside.
Search is test-time compute
autoresearch scales it
@hxiao · in/hxiao87


