Use HParams and YAML to Better Manage Hyperparameters in Tensorflow
Background
Building a machine learning system is an exploration-exploitation process. First, you explore some models, network architectures to check which one better fits the given problem. Once you have an idea, you concentrate on a particular model and exploit it by (manually/automatically) tuning its hyperparameters. Finally, the winner model with the best parameters will be deployed online to serve real customers. The whole process involves repetitively switching between different contexts and environments: e.g. training, validating and testing; local and remote; CPU, GPU, multi-GPU. As a consequence, how to effectively manage the configuration as well as the model hyperparameters becomes important. A good practice will definitely boost your exploration-exploitation process, easing the transition of your model into production.
In this post, I will describe a good way to manage the hyperparameters using Tensorflow’s HParams and YAML, which enjoys the following advantages:
- human-readable configuration
- allow multiple environments/contexts
- easy to maintain and extend
- light in terms of code
What is YAML and Why not JSON?
YAML is a human friendly data serialization standard for all programming languages. The following code shows an example of a YAML file:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19default:
batch_size: 100
split_ratio: 0.9 # training/validation ratio
train_embedding: true
cell: sru # simplified recursion unit
init_state_type: var
dilation: [1, 2, 4, 8, 16, 32]
num_hidden: 128
metric: cosine
num_epoch: 1000
optimizer: rmsp
learning_rate: 1.0e-4
decay_rate: 0.97
test_interval: 1
loss: logisitc
large_hidden:
<<:
num_hidden: 1024
In this example, I defined two sets of parameters, i.e. default and large_hidden. An immediate observation is that this file is visually easier to look at than its JSON counterpart, which is usually surrounded by lots of double quotes and braces. Besides, YAML does support comments. This definitely helps others to understand the meaning of your parameters better. Yet most importantly, YAML has the ability to reference other items within a YAML file using “anchors”. By specifying default with &DEFAULT anchor, large_hidden can be simply built by inserting all the key-value pairs from default to it (via <<: *DEFAULT), and then override the value of num_hidden. This is particularly useful as you can change few parameters without duplicating the entire parameter list. It is also more friendly to git-diff.
Load YAML into HParams
To use YAML configs in your python code, we need the class HParams defined in Tensorflow 1.4 API. A HParams object holds hyperparameters used to build and train a model, such as the number of hidden units in a neural net layer or the learning rate to use when training. It is very easy to use as you can directly access a parameter as a class attribute. For example:1
2hparams = HParams(learning_rate=0.1, num_hidden_units=100)
print(hparams.learning_rate) # print 0.1
To load our YAML configuration into HParams, we need a YAML parser and wrap it as follows:1
2
3
4
5
6
7
8
9
10
11
12
13
14from ruamel.yaml import YAML
from tensorflow.contrib.training import HParams
class YParams(HParams):
def __init__(self, yaml_fn, config_name):
super().__init__()
with open(yaml_fn) as fp:
for k, v in YAML().load(fp)[config_name].items():
self.add_hparam(k, v)
if __name__ == "__main__":
hparams = YParams('params.yaml', 'large_hidden')
print(hparams.num_hidden) # print 1024
And it’s done!
Best Practice: Separating Hyperparameters and App Configs
Although we can use one YAML to store hyperparameters and app configurations together, I don’t recommend to do so. App configuration specifies the environment setups, resources paths and security, which mostly are from engineering aspects. Separating these two also enables us to automatically search for the best hyperparameters using other ML libraries. Here is an example of an app config:
1 | local: |
To load app config and hyperparameters in one-shot, simply use YParams from above:1
2
3
4
5
6
7
8
9
10
11
12class ModelParams(YParams):
pass
class AppConfig(YParams):
def __init__(self, yaml_fn, config_name):
super().__init__(yaml_fn, config_name)
self.model_parameter = ModelParams(self.parameter_file, self.parameter_profile)
if __name__ == "__main__":
config = AppConfig('app.yaml', 'local')
print(config.work_dir) # /Users/hxiao/Documents/
print(config.model_parameter.num_hidden) # 128
If you are using Estimator API in Tensorflow 1.4, then importing these configs into the model becomes fairly easy. Simply use the following code:1
2
3
4
5
6
7
8
9import tensorflow as tf
def main(argv):
config = AppConfig('config.yaml', argv[1]) # argv[1] is the profile of configs
params = ModelParams('params.yaml', argv[2]) # argv[2] is the profile of params
model = tf.estimator.Estimator(model_fn=nade.model_fn, params=params)
if __name__ == "__main__":
tf.app.run()
A complete example using configs, Estimator and Dataset API can be found on my Github repo.
Summary
Having a good practice of managing configs and hyperparameters boosts the exploration-exploitation process when building a machine learning system. For example, I always store the evaluation results of each model in Line-delimited JSON (JSONL), and later visualize them in an interactive chart/table, e.g. check out the benchmark page of Fashion-MNIST.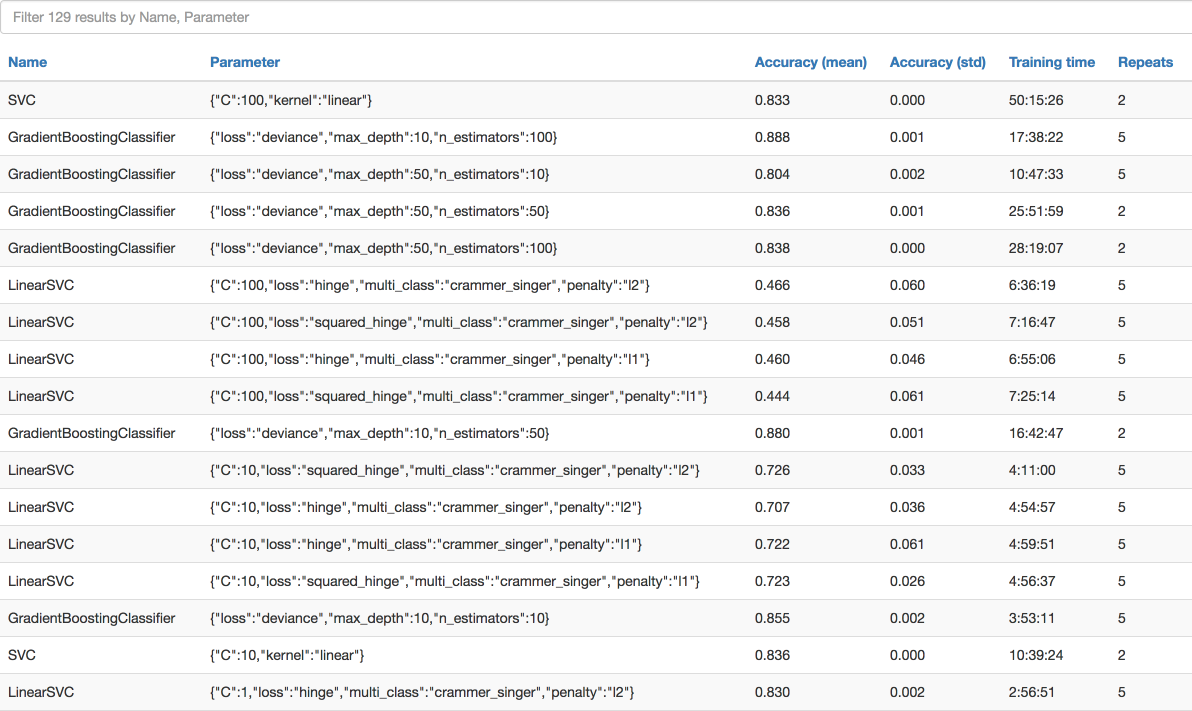
Finally, separating app configs from hyperparameters improves the collaboration between engineers and scientists in your team, easing the transition of a ML model into production.