Video Semantic Search in Large Scale using GNES and Tensorflow 2.0
Background
Many people may know me from bert-as-service (and of course from Fashion-MNIST </bragging>). So when they first heard about my new project GNES: Generic Neural Elastic Search, people naturally think that I’m building a semantic text search solution. But actually, GNES has a more ambitious goal to become the next-generation semantic search engine for all content forms, including text, image, video and audio. In this post, I will show you how to use the latest GNES Flow API and Tensorflow 2.0 to build a video semantic search system. For the impatient, feel free to watch the teaser video below before continue reading.
- Formulating the Problem in GNES Framework
- Preprocessing Videos
- Encoding Chunks into Vectors
- Indexing Chunks and Documents
- Scoring Results
- Putting it All Together
- Summary
I plan to have a series on the topic of video semantic search using GNES. This article serves as the first part. Readers who are looking for benchmarking, evaluations and models comparision, stay tuned.
Formulating the Problem in GNES Framework
The data we are using is Tumblr GIF (TGIF) dataset, which contains 100K animated GIFs and 120K sentences describing visual contents. Our problem is the following: given a video database and a query video, find the top-k semantically related videos from the database.
 |
 |
 |
| A well-dressed young guy with gelled red hair glides across a room and scans it with his eyes. | a woman in a car is singing. | a man wearing a suit smiles at something in the distance. |
“Semantic” is a casual and ambiguous word, I know. Depending on your applications and scenarios, it could mean motion-wise similar (sports video), emotional similar (e.g. memes), etc. Right now I will just consider semantically-related as as visually similar.
Text descriptions of the videos, though potentially can be very useful, are ignored at the moment. We are not building a cross-modality search solution (e.g. from text to video or vice versa), we also do not leverage textual information when building the video search solution. Nonetheless, those text descriptions can be used to evaluate/compare the effectiveness of the system in a quantitative manner.
Putting the problem into GNES framework, this breaks down into the following steps:
Index time
- segment each video into workable semantic units (aka “Chunk” in GNES);
- encode each chunk as a fixed-length vector;
- store all vector representations in a vector database.
Query time
- do steps
1,2in the index time for each incoming query;- retrieve relevant chunks from database;
- aggregate the chunk-level score back to document-level;
- return the top-k results to users.
If you find these steps hard to follow, then please first read this blog post to understand the philosophy behind GNES. These steps can be accomplished by using the preprocessor, encoder, indexer and router microservices in GNES. Before we dig into the concrete design of each service, we can first write down these two runtimes using the GNES Flow API.
1 | num_rep = 1 |
One can visualize these flows by flow.build(backend=None).to_url(), which gives:
Index flow
Query flow

More usages and specifications of GNES Flow API can be found in this post. We are now moving forward to the concrete logic behind each component.
Preprocessing Videos
In the previous post, I stated that a good neural search is only possible when document and query are comparable semantic units. The preprocessor serves exactly this purpose. It segments a document into a list of semantic units, each of which is called a “chunk” in GNES. For video, a meaningful unary chunk could a frame or a shot (i.e. a series of frames that runs for an uninterrupted period of time). In Tumblr GIF dataset, most of the animations have less than three shots. Thus, I will simply use frame as chunk to represent the document.
GNES itself does not contain such preprocessor (implementing all possible preprocessors/encoders is also not the design philosophy of GNES), so we need to write our own. Thanks to the well-designed GNES component API, this can be easily done by inheriting from the BaseImagePreprocessor and implement apply(), for example:
1 | from gnes.component import BaseImagePreprocessor |
This preprocessor loads the animation, reads its frames into RGB format, resizes each of them to 96x96 and stores in doc.chunks.blob as numpy.ndarray. At the moment we don’t implement any keyframe detection in the preprocessor, so every chunk has a uniform weight, i.e. c.weight=1.



One may think of more sophisticated preprocessors. For example, smart sub-sampling to reduce the number of near-duplicated frames; using seam carving for better cropping and resizing frames; or adding image effects and enhancements. Everything is possible and I will leave these possibilities to the readers.
Encoding Chunks into Vectors
In the encoding step, we want to represent each chunk by a fixed-length vector. This can be easily done with the pretrained models in Tensorflow 2.0. For the sake of clarity and simplicity, we will employ MobileNetV2 as our encoder. The pretrained weights on ImageNet are downloaded automatically when instantiating the encoder in post_init. The full list of pretrained models can be found at here.
1 | from gnes.component import BaseImageEncoder |
Code should be fairly straightforward. I create a new encoder class by inherit from BaseImageEncoder, in which the most important function encode() is simply calling the model to extract features. The batching decorator is a very handy helper to control the size of the data flowing into the encoder. After all, OOM error is the last thing you want to see.
Indexing Chunks and Documents
For indexing, I will use the built-in chunk indexers and document indexers of GNES. Chunk indexing is essentially vector indexing, we need to store a map of chunk ids and their corresponding vector representations. As GNES supports Faiss indexer already, you don’t need to write Python code anymore. Simply write a YAML config vec.yml as follows:1
2
3
4
5
6
7
8!FaissIndexer
parameters:
num_dim: -1 # automatically determined
index_key: HNSW32
data_path: $WORKDIR/idx.binary
gnes_config:
name: my_vec_indexer # a customized name
work_dir: $WORKDIR
As eventually in the query time, we are interested in documents not chunks, hence the map of doc id and chunk ids should be also stored. This is essentially a key-value database, and a simple Python Dict structure will do the job. Again, only a YAML config doc.yml is required:
1 | !DictIndexer |
Note that the doc indexer does not require the encoding step, thus it can be done in parallel with the chunk indexer. Notice how chunk_proc is broadcasting its output to the encoder and doc indexer, and how a sync barrier is placed afterwards to ensure all jobs are completed.

Scoring Results
Scoring is important but hard, it often requires domain-specific expertise and many iterations. You can simply take the average all chunk scores as the document score, or you can weight chunks differently and combine them with some heuristics. In the current GNES, scorer or ranker can be implemented by inheriting from BaseReduceRouter and overriding its apply method.
When designing your own score function, make sure to use the existing ones from gnes.score_fn.base as your basic building blocks. Stacking and combining these score functions can create a complicated yet explainable score function, greatly reducing the effort when debugging. Besides, all score functions from gnes.score_fn.base are trainable (via .train() method), enabling advanced scoring techniques such as learning to rank.
1 | class ScoreOps: |
Putting it All Together
With all the YAML config and Python module we just made, we can import them to the flow by specifying py_path and yaml_path in the flow. Besides scale out the preprocessor and encoder to 4, I also make a small tweak in the flow: I added a thumbnail preprocessor thumbnail_proc to store all extracted frames in a row as a JPEG file.
1 | replicas = 4 |
Visualizing these two flows give:
Index flow
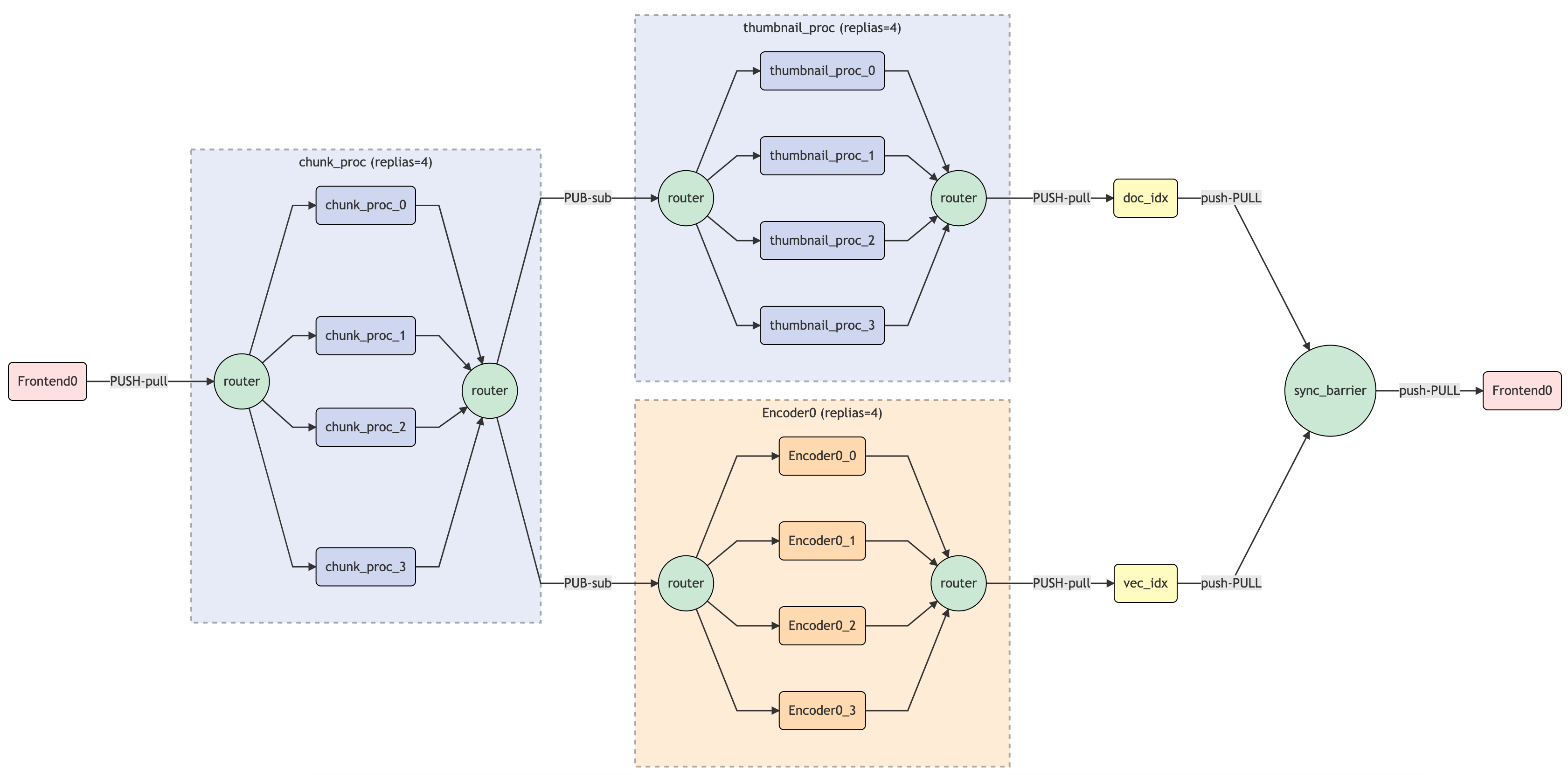
Query flow
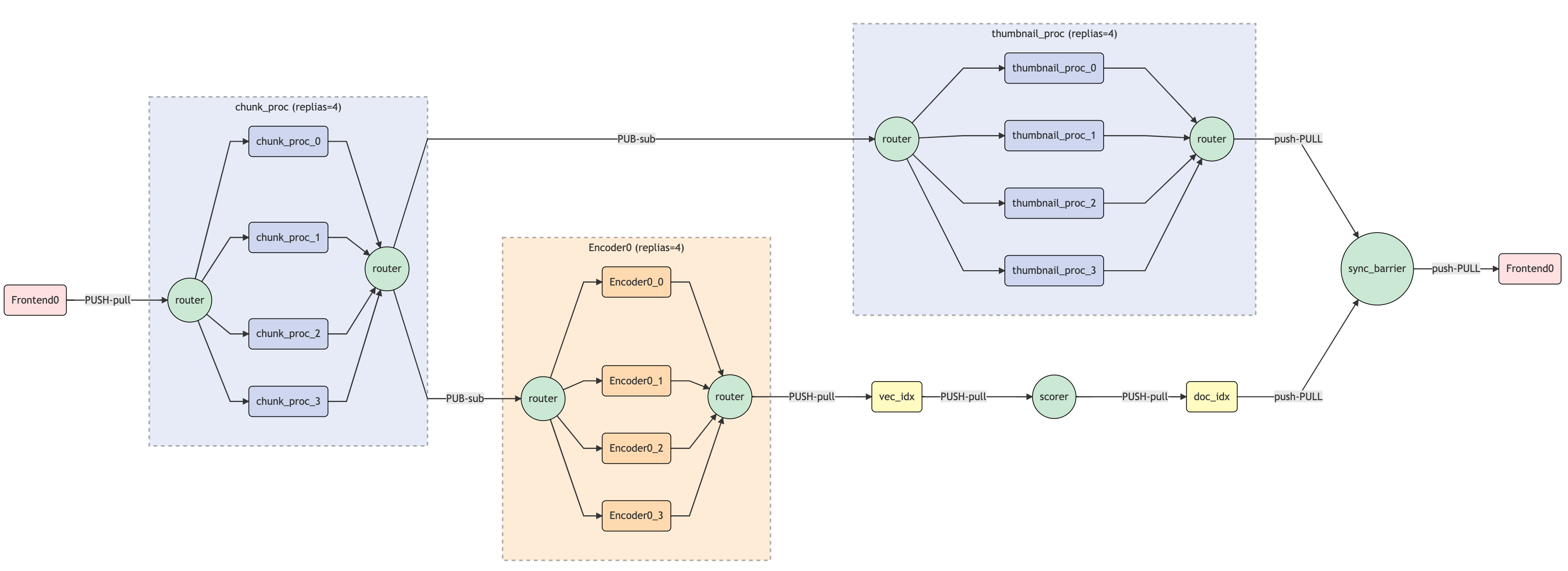
What Should We Send/Receive?
Sending data to the flow is easy, simply build a Iterator[bytes] and feed to flow.index(). The example below get the absolute paths of all animation files and send those paths to the flow:
1 | bytes_gen = (g.encode() for g in glob.glob('dataset/*.gif')) |
Of course one can first read() the animation into the memory, and send binary animation directly to the flow. But that will give very poor efficiency. We do not want IO ops to be the bottleneck, and that’s why we spawn four preprocessors in the flow.
The indexing procedure is pretty fast. On my i7-8850H desktop with no GPU, indexing the full dataset (~100K videos) takes 4 hours. Things can be much faster if you have a powerful GPU.
Once the flow is indexed, we can throw a video query in it and retrieve relevant videos. To do that, we randomly sample some videos as queries:
1 | bytes_gen = (g.encode() for g in random.sample(glob.glob(GIF_BLOB), num_docs)) |
Note that callback=dump_result_to_json in the code. Every time a search result is returned, this callback function will be invoked. In this example, I simply dump the search result into the JSON format so that I can later visualize it in the web frontend.
1 | fp = open('/topk.json', 'w', encoding='utf8') |
Summary
Video semantic search is not only fun (seriously I have spent even more time on watching cat videos after building this system), but has many usages in the customer facing applications, e.g. short videos apps, movie/film editors. Though it is too early to say GNES is the defacto solution to video semantic search, I hope this article sends a good signal: GNES is much more beyond bert-as-service, and it enables the search of almost any content form including text, image, video and audio.
In the second part, I will use the token-based similarity of textual descriptions (e.g. Rouge-L) as the groundtruth to evaluate our video search system. I also plan to benchmark different pretrained models, preprocessors, indexers and their combinations. If you are interested in reading more on this thread or knowing more about my plan on GNES, stay tuned.