






5x Speedup on CICD via Github Action's Strategy.Matrix
Background
No one likes to wait for 40 minutes on testing a pull request. You may make a coffee, flirt with your cat, read memes on the first few times, but I’m pretty sure your work ethic will eventually catch up: this isn’t right, and we need to optimize it now!
At Jina AI, we were facing this issue. As an open-source company, we have all our code infrastructures on Github and rely on Github Actions a lot (we even published two Actions in the marketplace). Our CICD workflows for jina-ai/jina have consisted of 15 files with almost 1-KLOC. We employ pytest and docker for conducting unit, integration, and regression tests. Starting from Feb. 2020, the community and our team continuously add tests while developing Jina, and today we have reached 85% code-coverage on 13-KLOC of Python code. However, this comes with a cost: on every commit to a pull request we have to wait for 40 minutes for its test result. It greatly slows down our development speed and prolongs the community’s feedback cycle. As a fast-growing OSS startup, this is unacceptable to us.
This post will show you how to use strategy.matrix and Github Packages to reduce the time on Github workflows significantly. For us, these tricks manage to cut our testing time from 40 minutes to 8 minutes! You can find out the complete script in our repository here.
Table of Contents
- Understanding the Test Structure
- Building Job Matrix for Parallelization
- Improvement on Testbed: Docker Build
- Summary
Jina is an easier way for enterprises and developers to build cross-/multi-modal neural search systems on the cloud. You can use Jina to build a text/image/video/audio search system in minutes. Give it a try:

Understanding the Test Structure
Initially, our Github workflow ci.yml looks like the following:
ci.yml | Visualization | ||
|---|---|---|---|
|  |
One can observe that the workflow already runs the unit and integration tests in parallel. Apparently, this is not enough. We need further parallelization on a finer granularity. But first, let’s look at the structure of our tests folder:
| Folder | Purpose | Structure | Size |
|---|---|---|---|
tests/unit | Unit test on each module | Sub-folders are organized by modules’ structure | Big |
tests/integration | Integration & regression test on each module | Sub-folders are organized by modules’ structure/Github issues number/test scenarios | Big |
tests/distributed | Integration test on distributed environment using docker-compose | Sub-folders are organized by network topologies | Medium |
tests/jinad | Unit test on Jina Daemon | Subfolders are organized by modules’ structure | Small |
tests/jinahub | Integration test on Jina Hub | No sub-folder | Small |
Given that all tests listed above are written in pytest, and they are unevenly distributed over different folders, one may think of leveraging pytest plugins (e.g. pytest-parallel, pytest-xdist) to parallelize it per test-case. However, this method does not leverage the scalable Github workflow infra it offers. After all, you are still running everything on one machine. Besides, we also prefer a controllable and clean environment on every running to ensure zero side effects on each test. The zero side effect is vital to Jina, as Jina is a decentralized system that creates & destroys ports/sockets/workspaces while running. Too many tests running parallel on the same namespace may introduce flakiness into the CI.
Building Job Matrix for Parallelization
The strategy.matrix is a powerful syntax in Github workflow. It allows you to create multiple jobs by performing variable substitution in a single job definition. For example, you can use a matrix to create jobs for Python 3.7, 3.8 & 3.9 (as shown in the above). Github action will reuse the job’s configuration and create three jobs running in parallel. A job matrix can currently generate a maximum of 256 jobs per workflow run, which is far beyond enough in our case.
In a nutshell, we want to fill in strategy.matrix as follows:
1 | core-test: |
Of course, no one wants to hardcode these test paths into the workflow YAML; we need a better way to dynamically fill in the values into strategy.matrix.test-path. Two problems here:
How to get those test paths?
This can be done by listing all sub-folders and orphan tests in a simple shell script1
2
3
4
5
6# get orphan tests under 1st level folders
declare -a array1=( "tests/unit/*.py" "tests/integration/*.py" "tests/distributed/*.py" )
# get all 2nd-level sub-folders, exclude python cache
declare -a array2=( $(ls -d tests/{unit,integration,distributed}/*/ | grep -v '__pycache__' ))
# combine these two and put them into an array
dest1=( "${array1[@]}" "${array2[@]}" )How to pass the value to
strategy.matrix.test-path?
Thanks to this feature introduced in April 2020, one can now usefromJSONto take a stringified JSON object and bind it to a property. Combining this withjob.outputswe can build a workflow that has a fully dynamic matrix.We need to adapt the shell script above and convert our shell array into a stringified JSON using our good old friend
jq: a JSON parser in command-line:1
printf '%s\n' "${dest[@]}" | jq -R . | jq -cs .
This will give you something as follows:
1
["tests/unit/*.py","tests/integration/*.py","tests/distributed/*.py","tests/distributed/test_against_external_daemon/","tests/distributed/test_index_query/","tests/distributed/test_index_query_with_shards/",...]
Putting everything together, we first prepare all test paths in a separate job say prep-testbed, and then in the testing job we load the paths from the output of prep-testbed into strategy.matrix. Consequently, our new workflow YAML can now be written as follows:
1 | commit-lint: |
Note the job dependency of core-test on prep-testbed specified by needs keyword. Once commit your new workflow, Github will start creating many parallel jobs as follows:
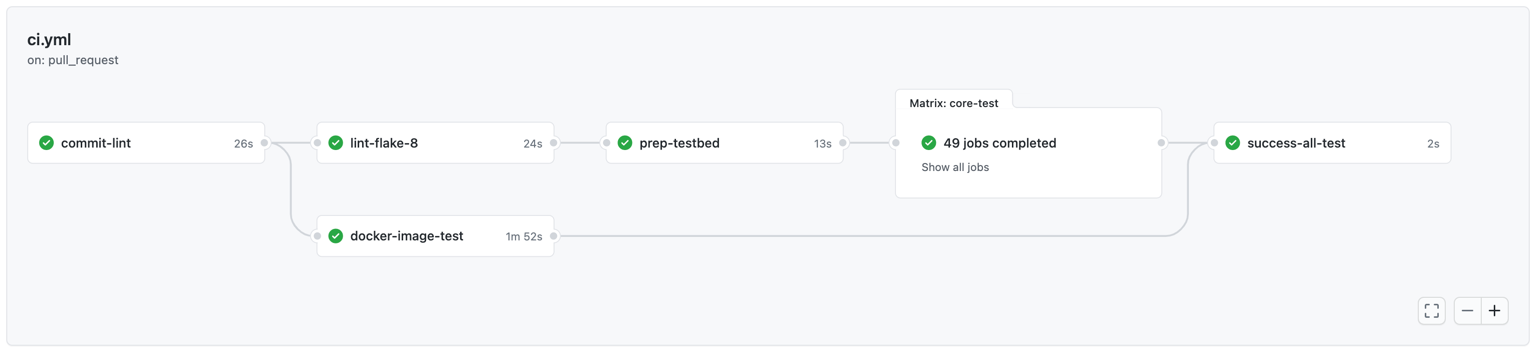
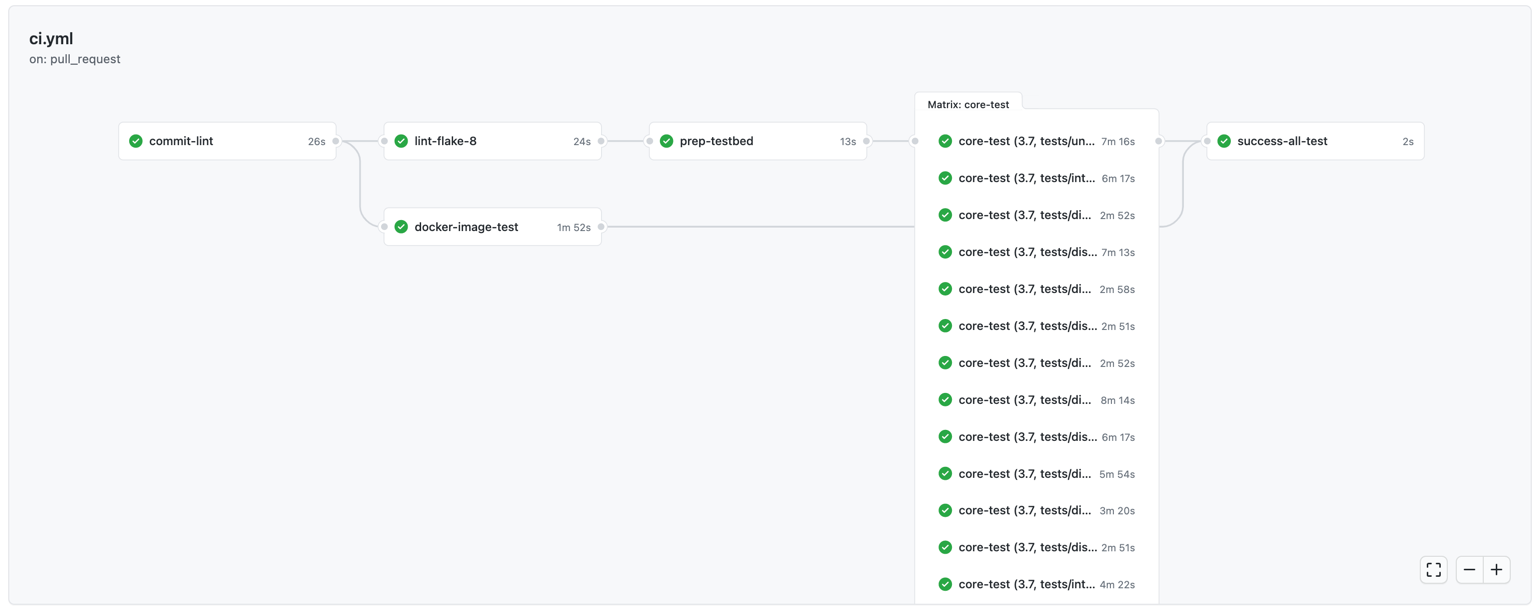
Improvement on Testbed: Docker Build
One immediate benefit of the parallel workflow is that you can quickly locate the first failed test without running over all tests. If you still prefer an exhaustive test, add fail-fast: false to strategy.
Docker Push to Github Packages
Some of our tests require a pre-built Jina Docker image running as a detached container in the background. One can easily add this step to the prep-testbed job. The following YAML config build the image based on the current head and then upload it to Github Package. The core-test job then pulls this image before conducting any test. Here we choose Github Package over Docker Hub to leverage the faster delivery network inside Github:
1 | prep-testbed: |
Note that we name the image with a unique environmental variable env.GITHUB_RUN_ID in the building time. This ensures that tests from different PRs are using their corresponding Docker images. In the core-test job after pulling the image, we immediately re-tag the image as jinaai/jina:test-pip before conducting any test. Hence, all test code can refer to the image as jinaai/jina:test-pip without specifying this unique ID.
Code Coverage
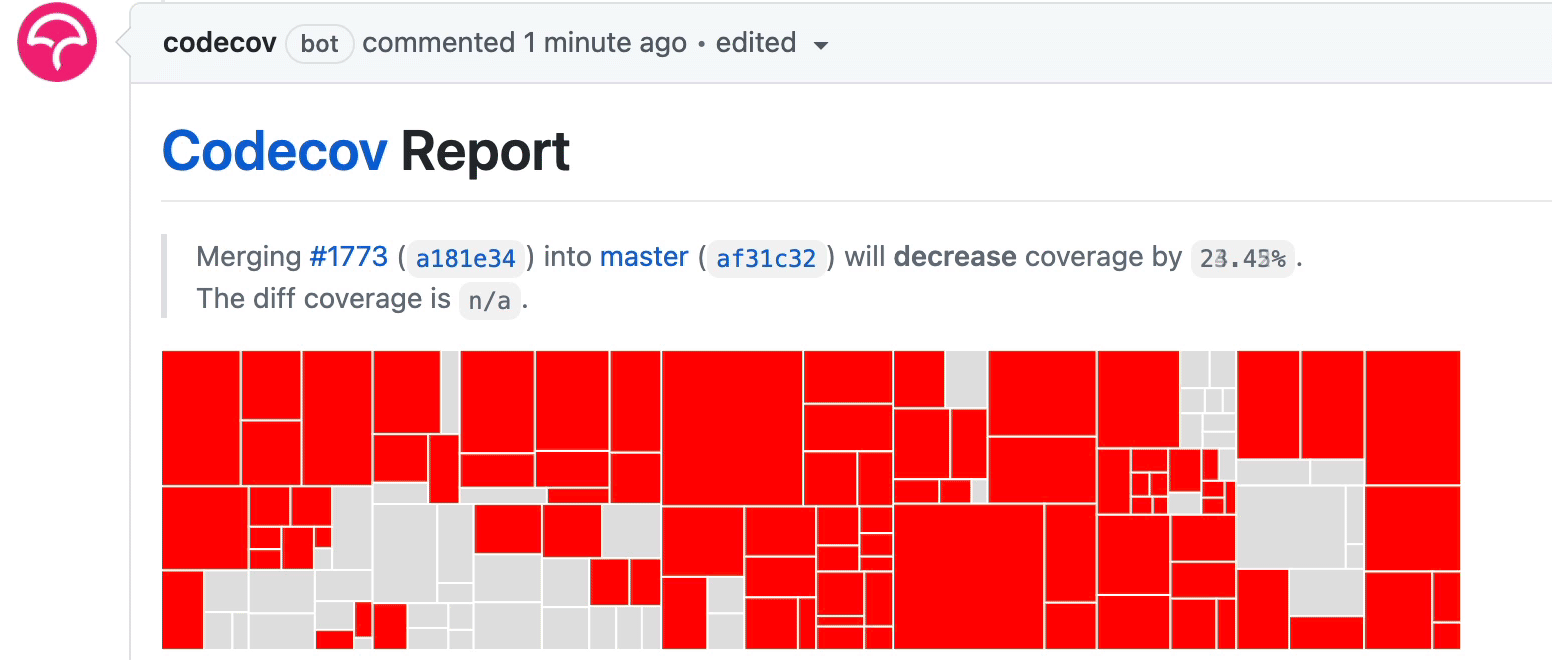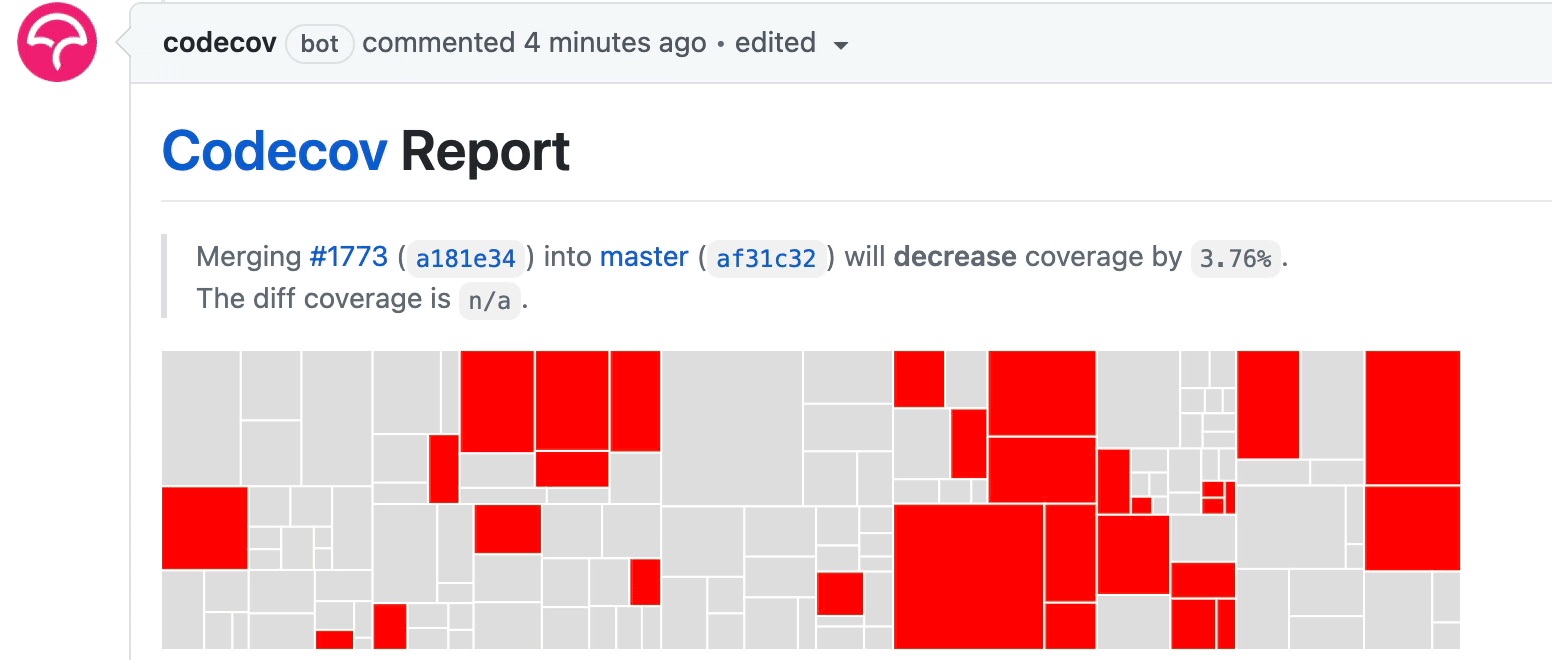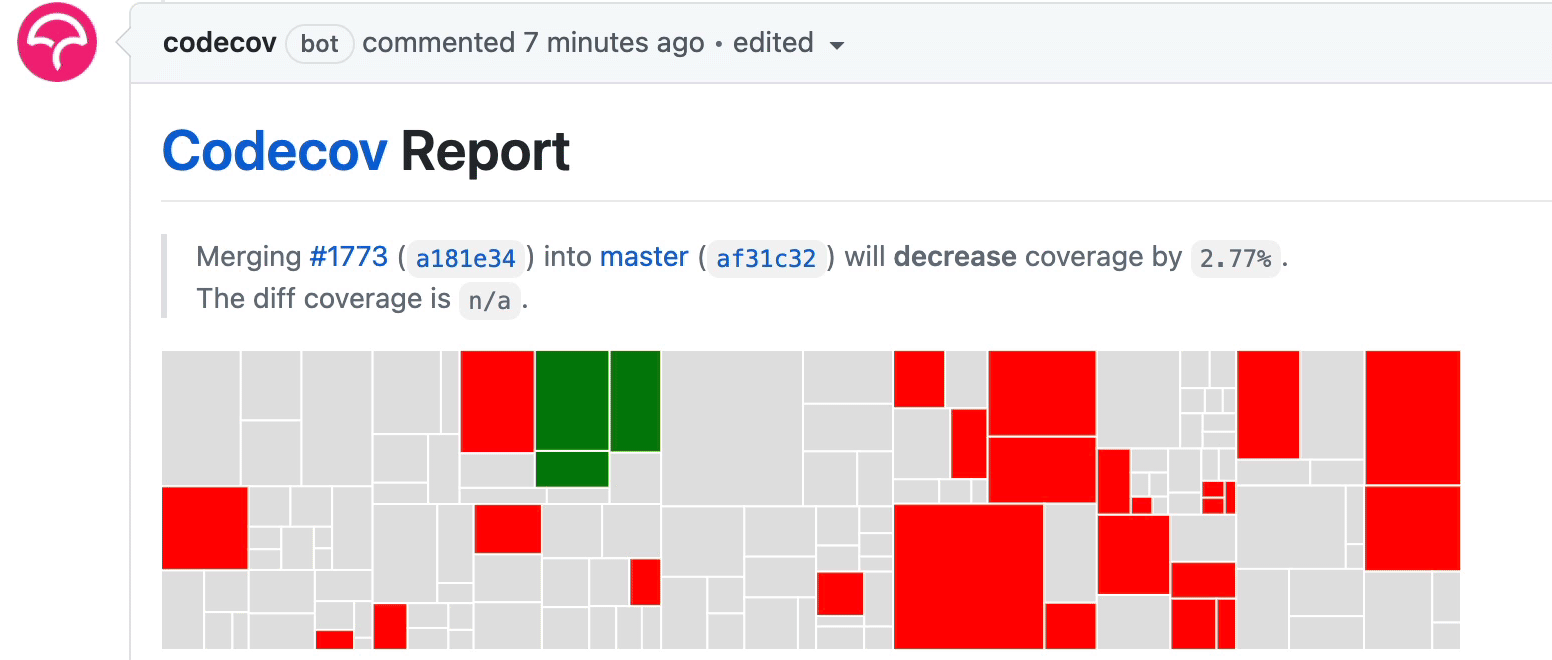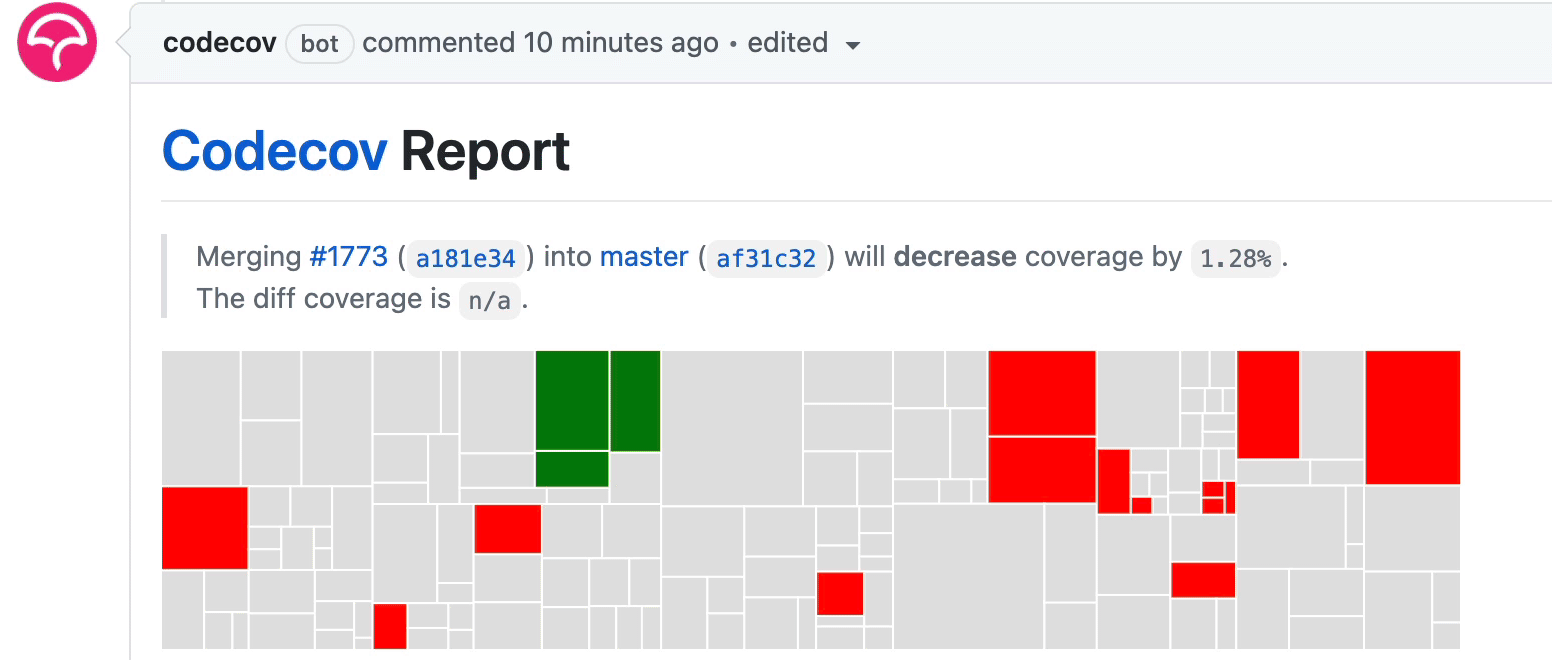
Careful readers may worry about the code coverage when using parallel workflow: if each job only tests against a small subset of the tests, how can they compute the code coverage correctly?
Fortunately, Codecov does not override report data for multiple uploads; it always merges the report data. It is common to test multiple build systems, split up tests in different containers, and group tests based on test focus.
1 | core-test: |
The workflow above uploads the code coverage report after each test group is done. As some test groups finish earlier whereas others are slower, you will see the coverage report updates incrementally under the PR as follows:
Summary
In this post, I have demonstrated how to use strategy.matrix to improve the Github workflow speed. Optimization like this is ranked as the highest priority at Jina AI: getting it done will improve the whole engineering team’s efficiency, saving hundreds of minutes per day.
Note that in a parallel workflow like this, the overall test time equals the slowest group’s test time, which means if you put everything into one folder, making its workload significantly bigger than the other, then the benefit of parallelization is marginalized. However, uneven test workload is inevitable in practice, and let’s say simple automation can only bring us so far. Therefore, some best practice needs to be followed:
- spread your test workload evenly across folders;
- for a big test folder, split it into sub-folders based on test focus.
If you’d like to explore more ML/AIOps techniques in practice, welcome to join our monthly Engineering All Hands via Zoom or Youtube live stream. Previous meeting recordings can be found on our Youtube channel. If you like Jina and want to join us as a full-time AI / Backend / Frontend developer, please submit your CV to our job portal. Let’s build the next neural search ecosystem together!