






Primitive Data Types in Neural Search System
A primitive data type is a data type for which the programming language provides built-in support. When it comes to framework design, primitive types often refer to the basic building blocks, allowing more complicated composite types to be recursively constructed. Examples such as ndarray in Numpy, tensor in Tensorflow: when writing a Numpy or Tensorflow program, the main object manipulated and passed around is those primitive data types.
What is the primitive data type in Jina then? To many readers and users of Jina, the concept of Executor, Driver, Pea, Pod, Flow should be very familiar. They define different abstraction layers, and together they compose the neural search design patterns. Thanks to these Jina idioms, one can quickly bootstrap a cross/multi-modality search system in no time. But are they primitive data types? No. Before v0.8, Jina has no primitive data type: drivers directly work with Protobuf messages for generating or parsing a stream of bytes in the network layer. The figure below illustrates this idea.
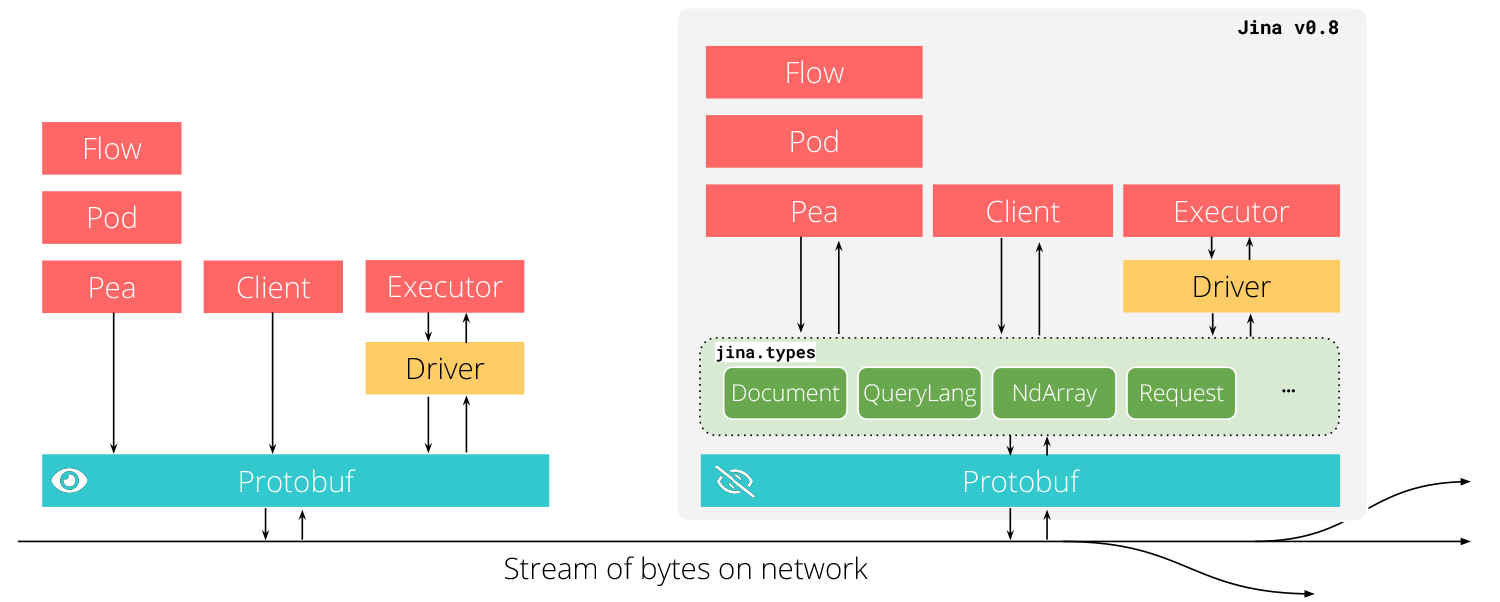
I will explain the new primitive data types Document, QueryLang, NdArray; and the composite types DocumentSet, QueryLangSet, Request, and Message in this blog post. These data types are available since v0.8 in the new jina.types module. Primitive data types complete Jina’s design by clarifying the low-level data representation in Jina, yielding a much simpler, safer, and faster interface on the high-level. Most importantly, they ensure the universality and extensibility for Jina in the long-term.
Jina is an easier way for enterprises and developers to build cross- & multi-modal neural search systems on the cloud. You can use Jina to bootstrap a text/image/video/audio search system in minutes. Give it a try:

Table of Contents
New Data Types
In v0.8, we introduced three primitive data types, four composite types, and some derived helper types.
Primitive Types
Documentis a basic data type for representing a real-world document. It can contain text, image, array, embedding, URI, and accompanied by rich meta information. It can be recurred both vertically and horizontally to have nested documents and matched documents.Documentis the main objectClientandDriverwork with. User creates it when preparing the input; and its lifetime spans over the entire indexing and searching processes in Jina.QueryLangis a basic data type for representing the query language structure.Clientcan useQueryLangto build filter/sort/select queries and convert from/toQLDriver.NdArrayis a basic data type for representing fixed-size multidimensional items of the same type. As the fundamental numeric type in Jina,NdArrayis often used to representembedding,blob, images, audios, texts; and joins the computation of other frameworks such asnumpy,tensorflow,pytorch.DenseNdArrayis a specific data type for the dense representation of aNdArray. Same asnumpy.ndarray, it contains values of all elements, the shape and the data type of each element. One can consider it as anumpy.ndarray“view” of the Protobuf data.DenseNdArrayalso provides a quantization interface to allow lossy compression.SparseNdArrayis a specific data type for sparse representation of aNdArray, where substantial memory requirement reductions can be realized by storing only the non-zero entries. Jinav0.8provides thescipy,tensorflow,pytorch“views” of the Protobuf data, which can directly join the corresponding framework’s computation.
Composite Types
Besides primitive data types, three new composite types provide boxing on primitive types. This enables a more Pythonic interface and keeps the data safe from outside interference and misuse.
DocumentSetis a mutable sequence ofDocument. It allows one to slice/modify/add/delete the sequence and iterate over its element via a generator.QueryLangSetis a mutable sequence ofQueryLang. LikeDocumentSet, it allows one to slice/modify/add/delete the sequence and iterate over its element via a generator.Requestis a data type for representing the message passing between Pods,ClientandGateway. It contains all data all Pods require, includingDocumentSet,QueryLangSetand meta information.Requestalso provides a lazy interface to the underlying Protobuf data, avoiding unnecessary (de)serialization and (de)compression. The lifetime ofRequestspans over the entire indexing and searching processes in Jina: it is the first object users send to Jina and the final object retrieved from Jina.Messageis a container of a ProtobufEnvelopeand the primitive typeRequest. It is the actual data type passing internally between Jina Pods.
The next figure illustrates the connections between those data types:
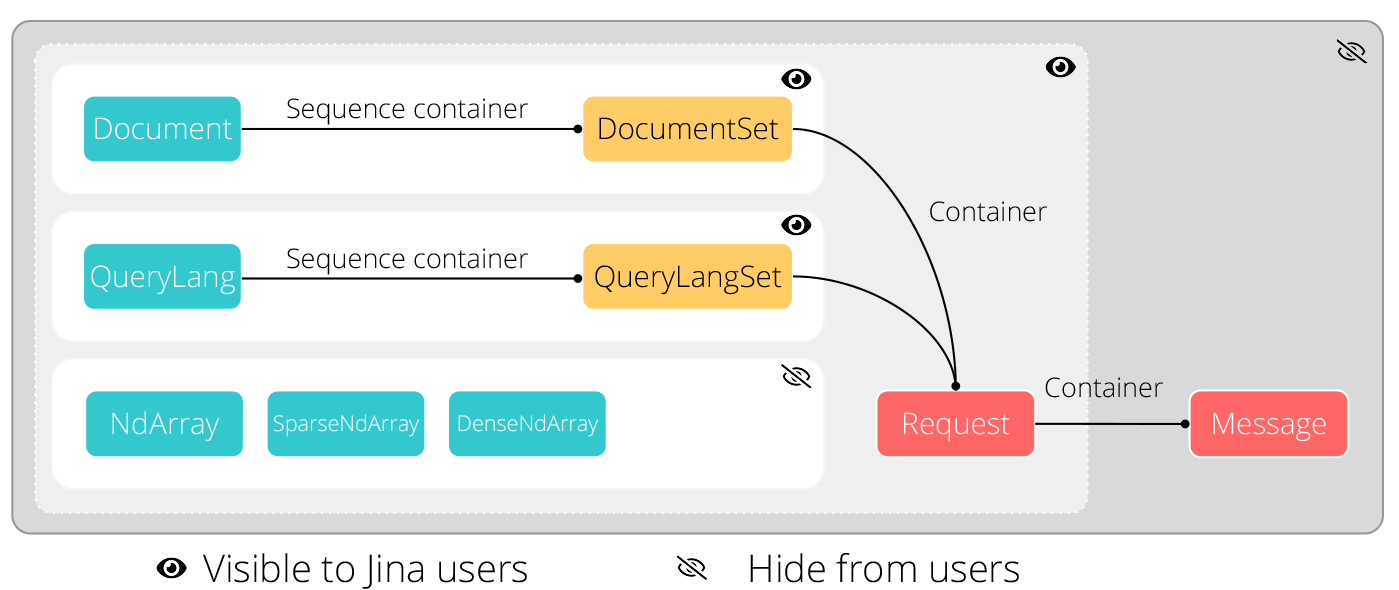
Jina Data Types In Action
Now let’s look at some examples. Say we have an image, and we want to create a Document to contain this image.
1 | # build a fake WHC image |
As a comparision, the new way versus the old way of creating such document:
Primitive Type in v0.8 | Before | ||||
|---|---|---|---|---|---|
|
| ||||
|
|
One can immediately notice that the new data type encapsulates the Protobuf access. That only scratches the surface of Jina data type. Let’s now see more usages.
Setting Content
1 | from jina import Document |
The MIME type of the document is auto-guessed from the content.
Converting Content Types
One can use convert_* methods to switch between different document content. The example below reads the content from README.md into text field.
1 | from jina import Document |
Construct From Existing Document
Document object can be constructed from existing Document-like structure, such as binary or JSON string, Dict or a DocumentProto Protobuf object:
1 | from jina import Document |
Unique Identifier of Document
Since Jina v0.6, every document has a unique identifier id associated with all contents of the document. This ensures same content documents always have the same id. With the new Document type, the content-aware id can be set via update_id(), or get auto set when using it as a context manager:
1 | from jina import Document |
Access Nested Document
Nested document can be accessed via properties chunks and matches. Both properties return a DocumentSet object, allowing one to access the nested documents as a Python List:
1 | from jina import Document |
Construct Query Language
In Jina v0.5, we have introduced a new set of drivers for enabling query languages. Those drivers allow the user to override its parameter to get alternative result. One example is top-k retrieval or pagination, where the start and the end position of result slicing is a parameter at query time. With the new QueryLang type, constructing a query language becomes extremely simple.
1 | from jina.drivers.querylang.slice import SliceQL |
Same as Document, a QueryLang object can be also constructed from binary or JSON string, Dict or a QueryLangProto object. To manage multiple QueryLang objects, one can use QueryLangSet similar to DocumentSet.
Construct Request
Putting everything together, constructing a Request on the client side becomes extremely easy and Pythonic:
1 | from jina import Request, Document, QueryLang |
Design Decisions
Finally, let’s review some design decisions made in Jina data types.
View, not copy.
As Protobuf object already provides a Python interface, which can be considered as a “storage” representation, we don’t want to copy it or add another storage layer. Otherwise, it will introduce data inconsistency between the Protobuf object and the Jina data type object. Our goal is to provide an enhanced “view” to the Protobuf “storage” by maintaining a reference.
The next figure uses Document as an example and visualizes the relations between primitive, composite, and Protobuf data types.

Delegate, not replicate.
Protobuf object provides attribute access already. For simple data types such as str, float, int, the experience is good enough. We do not want to replicate every attribute defined in Protobuf again in the Jina data type, but really focus on the ones that need unique logic or particular attention.
To delegate attribute getter/setter to Protobuf object, all Jina data types implement the following fallback:
1 | def __getattr__(self, name: str): |
More than a Pythonic interface.
Jina data type is compatible with the Python idiom. Moreover, it summarizes common patterns used in the drivers and the client and makes those patterns safer and easier to use. For example, doc_id conversion is previously implemented inside different drivers, which is error-prone. Another great example is the lazy access to Request. A Request object will trap all read/write access to its content. The serialization and decompression (to a Protobuf object) are only triggered when there is access. Otherwise, the deserialization and decompression are ignored, yielding more efficient message passing, especially on Peas equipped with RouteDriver.
If you’d like to find out more about Jina primitive data type or discuss the design pattern for neural search, welcome to join our monthly Engineering All Hands via Zoom or Youtube live stream. Previous meeting recordings can be found on our Youtube channel. If you like Jina and want to join us as a full-time AI / Backend / Frontend developer, please submit your CV to our job portal. Let’s build the next neural search ecosystem together!