






Layer of Abstraction When Building "Tensorflow" for Search
Background
Since Feb. 2020, I started a new venture called Jina AI. Our mission is to build an open-source neural search ecosystem for businesses and developers, allowing everyone to search for information in all kinds of data with high availability and scalability. At the core of this ecosystem is Jina: a framework that enables one to bootstrap cloud-native neural search in minutes, which otherwise would take months.
We have received quite some attention from the community since Jina came out of stealth in May. Early adopters include users of my previous projects bert-as-service, GNES, and Fashion-MNIST. Many of them expect Jina to be a one-liner solution to their problems, just like bert-as-service or other trending AI projects. Soon they realized that Jina is not a one-liner: it is a pretty versatile framework with a relatively steep learning curve. Perhaps our ambition is beyond their initial expectations, or perhaps the overwhelming documentation makes people feel nowhere to start with. Either way, one frequent question I receive is: what is Jina?
The purpose of this post is not only answering this question but also sharing our understanding of abstraction when building frameworks like Jina:
- Many computer science problems can be solved by adding another level of abstraction, especially when we want to improve the usability.
- Unlike one-liner and sugary API, Jina is shipped with multiple layers of abstractions; each layer targets a particular developer group.
- Features need to be implemented at the correct abstraction layer to solve the problem effectively.
Table of Contents
Jina is “Tensorflow” for Search
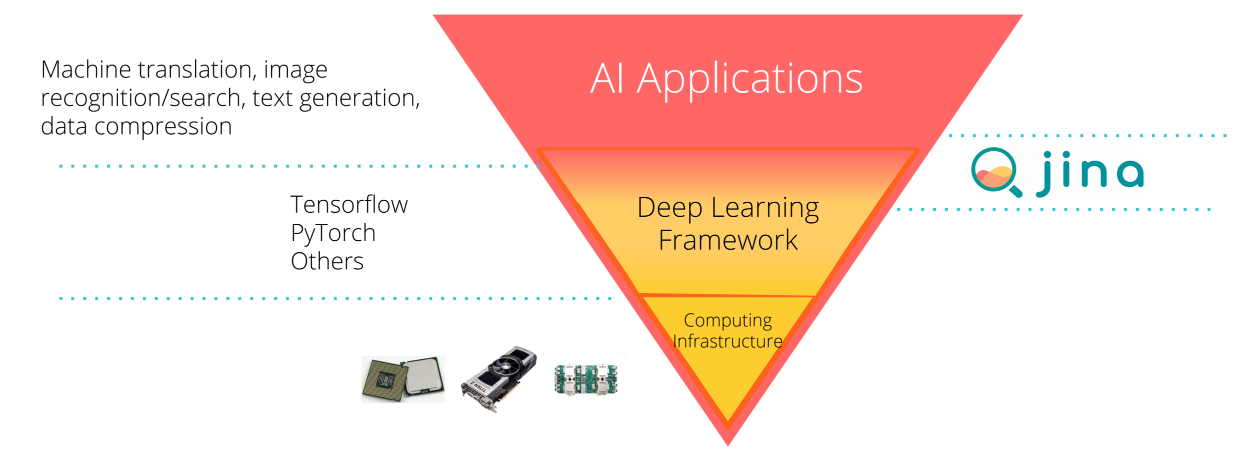
I often use the analogy “Tensorflow” for search to explain what Jina is. Jina sits one layer above the universal deep learning framework (e.g., Tensorflow, Pytorch, Mindspore); it provides the infrastructure for building AI-powered search applications. So the next time you develop a multi-/cross-modalities search app (question answering, image/video/audio search), Jina will be your go-to “programming language”. It helps you get the job done quickly and beautifully by providing you first-class support on AI models and rich cloud-native features.
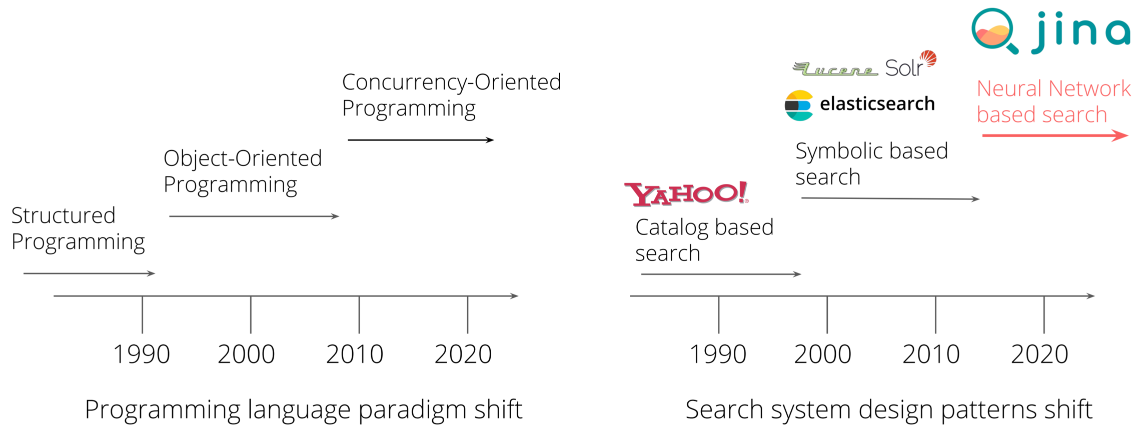
Every era has its design pattern, and this is what we observed from the evolution of programming languages. The same goes for the search system. Jina is built on the fact that today’s search queries are beyond simple keywords, and the underlying algorithms are often AI-centric. Comparing to legacy design patterns in the market, Jina provides modern and intuitive idioms for building neural search systems in production.
So, we are building Jina as a framework. Now we need to talk about the layer of abstraction in Jina.
Layer of Abstraction
There’s no problem in Computer Science that can’t be solved by adding another level of indirection (/abstraction) to it.
Abstraction is a commonly used in software design. By hiding the complexity and the real implementation in the lower level, higher-level API can often provide more readable code and shorter development time. One radical example is the “one-liner (or syntactic sugar or sugary API)” design, as we see in many trending AI projects. It provides user a single deceptively powerful entrypoint such as translate('hello world', target_lang='de'). While the ideal way for abstraction is to keep the versatility promised at lower levels, one-liner trades off much of the primitive versatility for exchanging extreme usability. However, despite being eye catching on social shares (thanks to Carbon.sh), one-liners often have limited use cases and are not production-ready.
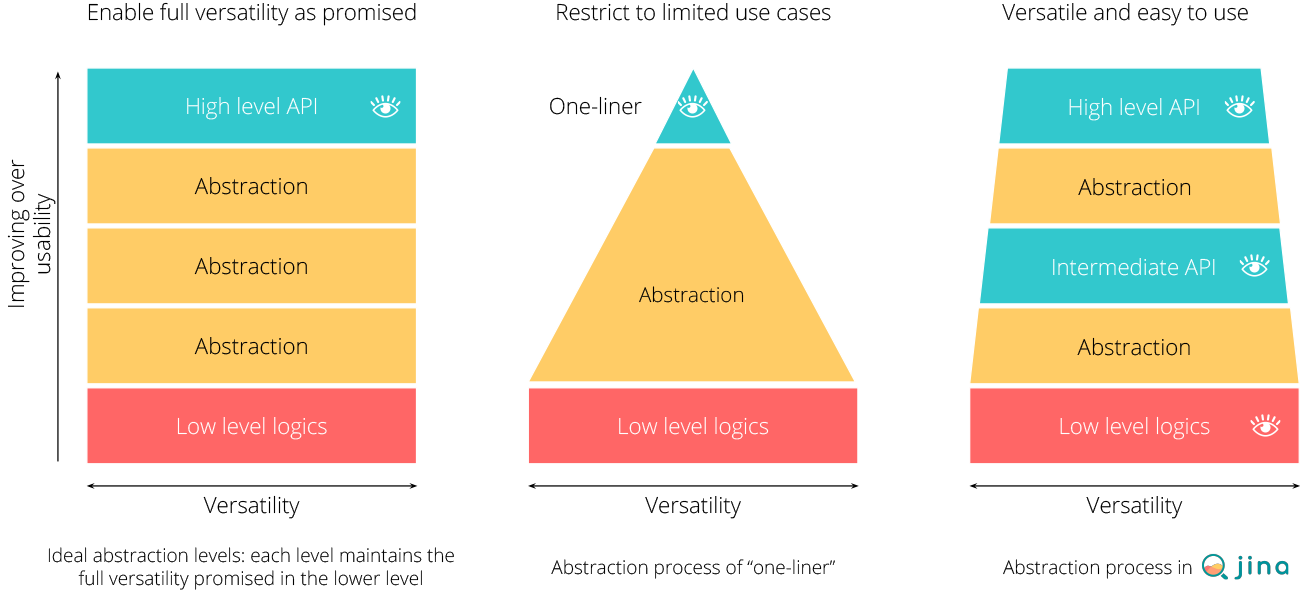
Jina follows a progressive way when doing abstraction. Unlike one-liners, Jina is shipped with multiple layers of abstractions, each layer targets a particular developer group. As a consequence, users can choose different levels of API to interact with Jina and accomplish the task. Designing and architecting Jina becomes finding what the essential complexity is, and then moving it around.
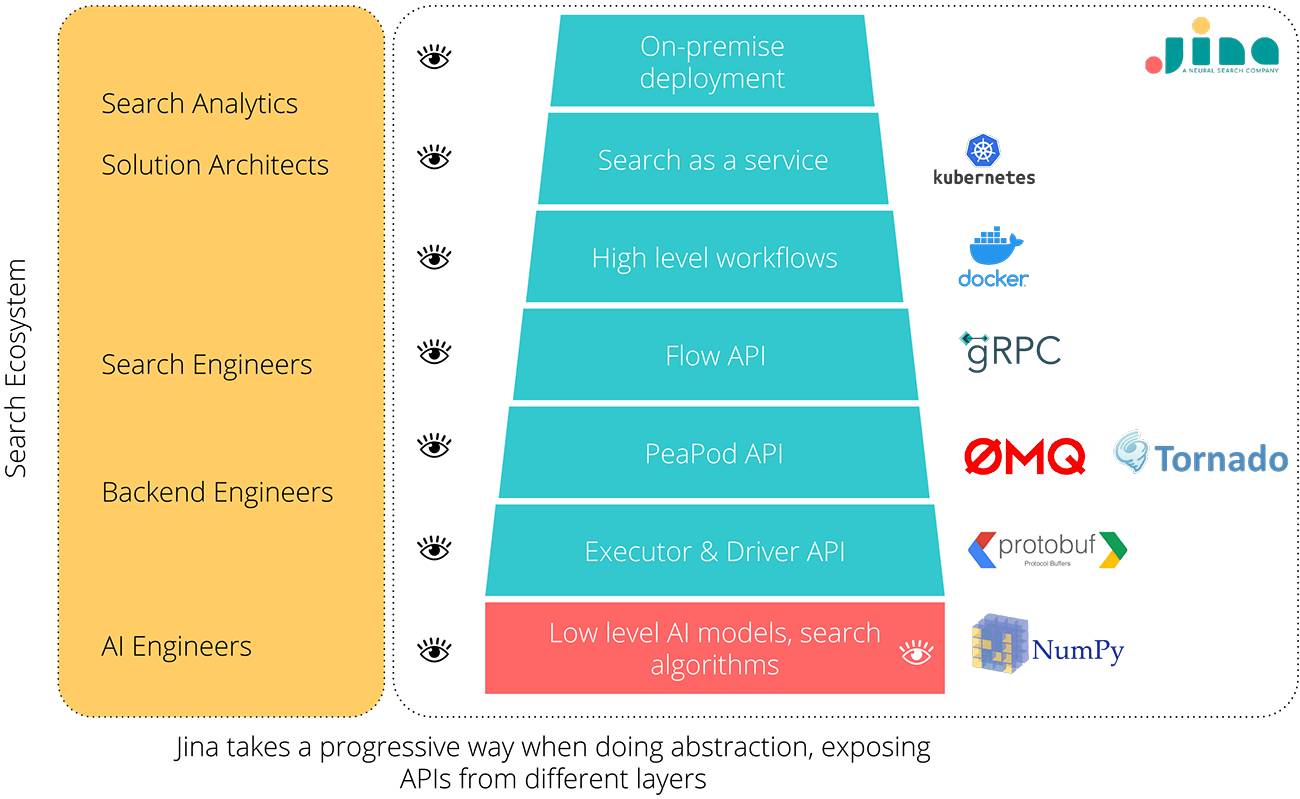
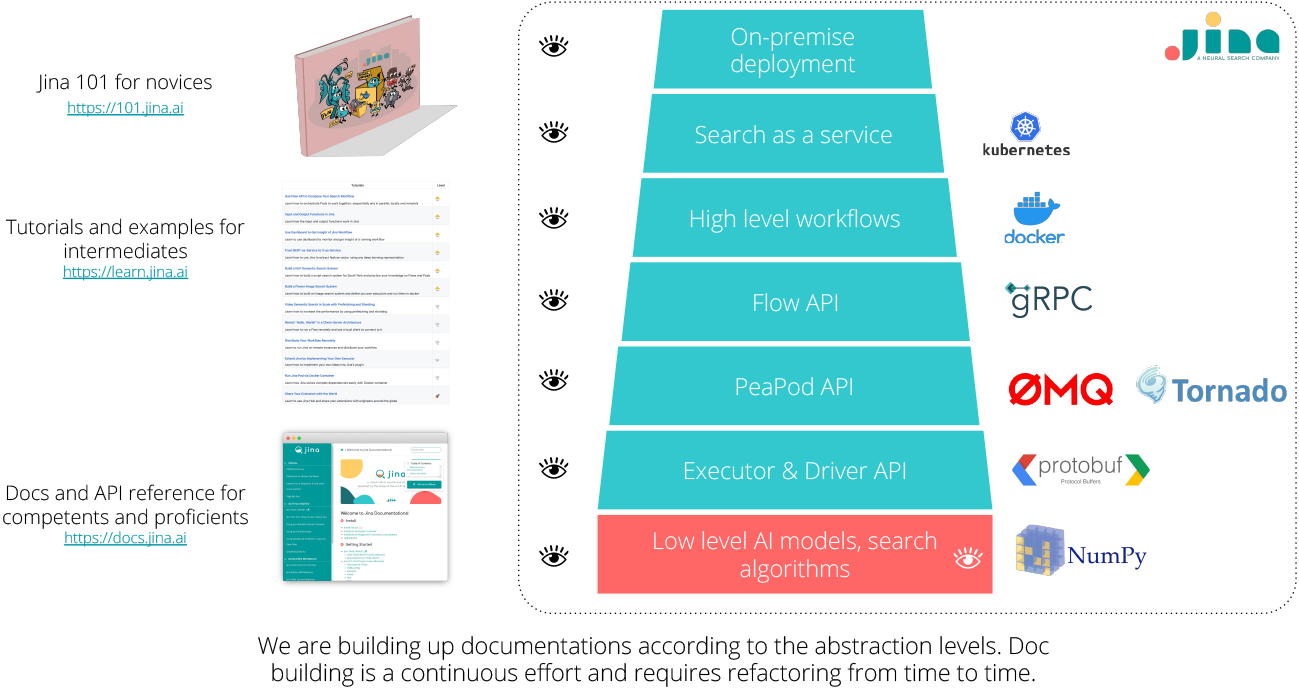
For example, Jina started with the concept of Executor to abstract the complexity behind AI models and unify their interfaces. This abstraction allows AI engineers to chain and compose models as they manipulate variables. AI models can be read from a YAML file and be invoked via simple interface, such as .encode(), .index(), .add(), .query(), .segment(). Later, Driver was added to grant Executor the read & write abilities on Protobuf message, while keeping Executor data-agnostic. Furthermore, with the help of Pea and Pod, developers can quickly deploy Executor in a decentralized way. They can parallelize it, containerize it, run it as an independent process or use it as a service. On top of that, Flow API provides a high level interface for orchestrating all Pod to achieve a certain task. In the end Jina exposes API at different levels, allowing developers to choose their niches. We see this design pattern appears in other frameworks as well. In Tensorflow, developers can use micro-level neural network operations in tf.nn, layers API in tf.keras.layers and macro-level network models in tf.estimator.
Engineering Challenges
- Implementing the right feature at the correct layer
- Managing and guiding community expectations
- Refactoring the documentation regularly
Implementing the right feature at the correct layer
With an architecture like Jina, the biggest challenge is implementing the right feature at the correct layer. Some features are in the very high-level hence they must be postponed until the low-level is ready. Some features have very vague relations to the end-user experience, yet they are enablers for many functionalities on the higher level. Hence, they have to be implemented right now. Some features are simply out of the scope of the product roadmap; they have to be delegated to third-party or implemented in another product.
The biggest decision often is not about what this API layer does do, but instead what it doesn’t do.
One example is the logging in Jina. Some users argue that the log printed in the console is overwhelming and hard to comprehend. Features such as log prettify, grouping and persistence are requested. Though we can squeeze rich debug info and prettify the console’s logs, this only works to a certain level. Users may soon realize they need extra customization and more professional log management when using Jina in production, making previously added features frivolous and wasteful. As a solution, Jina implemented a logger interface that can be used from low-level Executor up to high level Flow. The logger interface enables the emission of raw logs in JSON format to the network via Server Sent Events. One of our other products, Jina Dashboard then takes over the job. The dashboard subscribes to the log stream and does all the processing, grouping and analyzing work in Javascript.
Another example is cookiecutter-jina. This project aims to help developers to create Jina projects from predefined templates. It is a pretty high-level feature that sits on top of Flow API. However, due to the nature of complexity in Jina, we quickly realized that maintaining cookiecutter with a simple markup language (Jinja) isn’t the best idea. Today we are working on other solutions including GUI ones to help developers bootstrap a new project quickly.
Managing and guiding community expectations
The community often wants to get things done as quickly as possible. While the framework developers share the same ultimate goal, they have to take steps by first building lower layers steadily and robustly. When developing the framework as an open-source project, aligning the community expectation and being transparent on the roadmap is crucial.
Refactoring the documentation accordingly
When multiple abstractions are exposed, the concern about the complexity and length of documentation arises. The documentation of each API layer needs to be self-contained and explain its connection to the upper and lower levels. This extends the effort required to maintain and correct documentation throughout the lifecycle.
A good design of documentation will provide the correct entrypoint for each targeted user group, guiding them to the information they needed. This means not only optimizing on the UX level, but also showing/hiding/emphasizing particular sections, changing the narrative accordingly. Just like software, documentation is a continuous effort and has to be revisited and refactored from time to time.
Conclusion
With so many variables at play, complexity and abstraction is a natural part of framework design. In Jina, our everyday job includes rethinking complexity, decomposing it, hiding it, and moving it around; to ensure that features are more consumable and more apt for new developers and users.
I hope these thoughts on the abstraction could help the community to understand Jina better and shed light when people try to develop their own AI framework. If you want to see how Jina evolves and carries out those philosophical ideas into practice, make sure to check out our Github repository jina-ai/jina and give it a star. If you are interested in working with me, please send your CV to [email protected]. Let’s build the neural search ecosystem together in open source!