






Extremely Stupid Mistakes I Made With Tensorflow and Python
Background
Recently I started with Tensorflow for developing some RNN-based system. I choose Python 3 as the main language since TF has most stable API support for it. Plus, I can quickly set up web services via Flask and uWSGI. Previously I had some experience with this technology stack (Python+Flask+uWSGI) in production and I want to make it better this time. Although Java + Spring or Scala + akka may be better options for building a more scalable web app, they are probably overkill in my project, at least for now.
Building a highly scalable and available deep learning system is a topic for another day, here I want to talk about some mistakes I made when using Tensorflow with python. This section is expected to grow continuously as I’m still learning Tensorflow. Some mistakes are extremely embarrassing as they become such obvious once I understand them.
Mistake 1: I used dict.get() as switch-case
Python doesn’t have switch-case, which means you have to write a long if-elif-elif-else block to do switching. As I used Scala a lot in my last project, I really miss the powerful and functional pattern matching in Scala.
As a workaround, the highest-voted solution on StackOverflow teaches me to use dict.get:
1 | def f(x): |
Looks legit to me! And to follow this spirit, I wrote something like:
1 | def get_loss_node(loss_type: str): |
I use the Python 3 type annotation feature, that’s why you see str in the function argument. The main idea of this code snippet is to build different types of “loss node” in the Tensorflow computational graph according to the parameter loss_type. Comparing to the lame if-else block, I managed to save some lines. Pretty neat, right? Actually, NO!
The reason is: when you run this code, Python first constructs a dict variable with four items, each of which has a str key and tf.Tensor as value. Then it picks the one that matches the given loss_type. In other words, you create three useless nodes in the computational graph! To show how much time is wasted here, I made a small test.
1 | import tensorflow as tf |
which gives:
1 | foo1 takes 1.026s |
Our dict trick is about three times slower than the lame if-else. However, slowness isn’t the only problem, it also significantly complicates the computational graph and induce some error. See the example below, where I create a bidirectional RNN chain:
1 | fw_cell = rnn.LSTMCell(5) |
We can use Tensorboard to visualize the computational graph behind, the dict trick produces: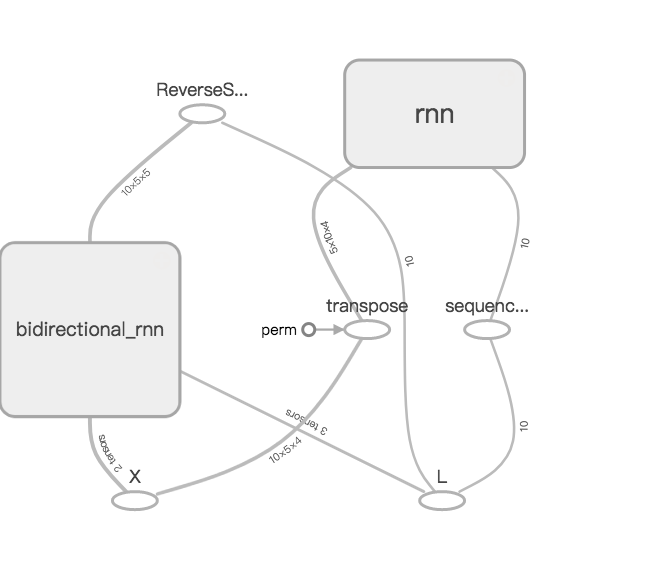
whereas the if-else gives a much simpler one: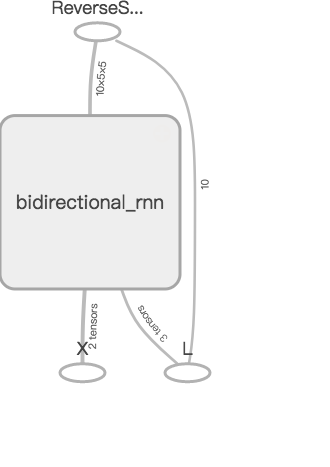
On the latest Tensorflow (> 1.1, probably starting from May 2017), the above code will also throw an error:
ValueError: Attempt to reuse RNNCell <tensorflow.contrib.rnn.python.ops.core_rnn_cell_impl.BasicLSTMCell object at 0x10210d5c0> with a different variable scope than its first use. First use of cell was with scope ‘rnn/multi_rnn_cell/cell_0/basic_lstm_cell’, this attempt is with scope ‘rnn/multi_rnn_cell/cell_1/basic_lstm_cell’. Please create a new instance of the cell if you would like it to use a different set of weights. If before you were using: MultiRNNCell([BasicLSTMCell(…)] * num_layers), change to: MultiRNNCell([BasicLSTMCell(…) for _ in range(num_layers)])
The reason is that
dict creates two RNN chains that share the same RNN cell, i.e. fw_cell.But I still want to be cool
How come I didn’t notice this before? Well, probably because I mainly used this trick on some simple task such as printing constants, where the side-effect of the dictionary construction is neglectable. But what if one still want to use this trick instead of writing the if-else block? lambda expression can be a workaround.
1 | def foo3(choice: str): |
In this code, I wrap the variable with a python lambda expression (i.e. an in-line function), so that the value of a dictionary item is a function handler rather than a TF variable. In fact, TF variable is not constructed until () is called (after [choice]). The speed test also shows that it takes the same time as if-else block.
1 | foo1 takes 1.132s |
Mistake 2: I used lambda expressions a lot
Do I and lambda expression live happily ever after? Well, until I realized that lambda expression is the main reason of low GPU utilization.
The code below employs lambda expression to unify the function arguments of different loss functions in a multi-label classification problem:
1 | my_loss = { |
rank_hinge_loss and rank_sigmoid_loss are customized loss function written by me, which could also be a topic on another day. sigmoid_cross_entropy_with_logits and weighted_cross_entropy_with_logits are Tensorflow built-in loss functions for multi-label problem which somehow have different names for the groundtruth (targets and labels). Anyway, by using lambda expression all those differences should go away, and we can just write something like:
1 | self.Y_logit = tf.add(tf.matmul(last, weight_o), bias_o, name='logit') |
However, when I deploy the code on a GPU instance, I found the GPU utilization is far from 100%. On average it’s only 20% utilization, and training speed is not faster than my 4-core laptop.
I added with tf.Session(config=tf.ConfigProto(log_device_placement=True)) as sess: and looked into the variable placement. Surprisingly, all loss-related TF variables are located on CPU not GPU, even though I force them to via with tf.device('/gpu:0'):.
1 | Loss_1/tags: (Const): /job:localhost/replica:0/task:0/cpu:0 |
Things did not change when I set loss_type = 'sigmoid' and used TF built-in loss. What is the problem?
The problem is by wrapping the loss function with a lambda expression, you make a TF variable / tensor / operator a standard Python function, which can not be efficiently evaluated on GPU with TF. As the loss function is evaluated in every iteration, this implementation is significantly slower than the standard TF loss operator. Once again, slowness is not the complete story. If we look at the computational graph with Tensorboard. The lambda version of sigmoid loss looks like this:
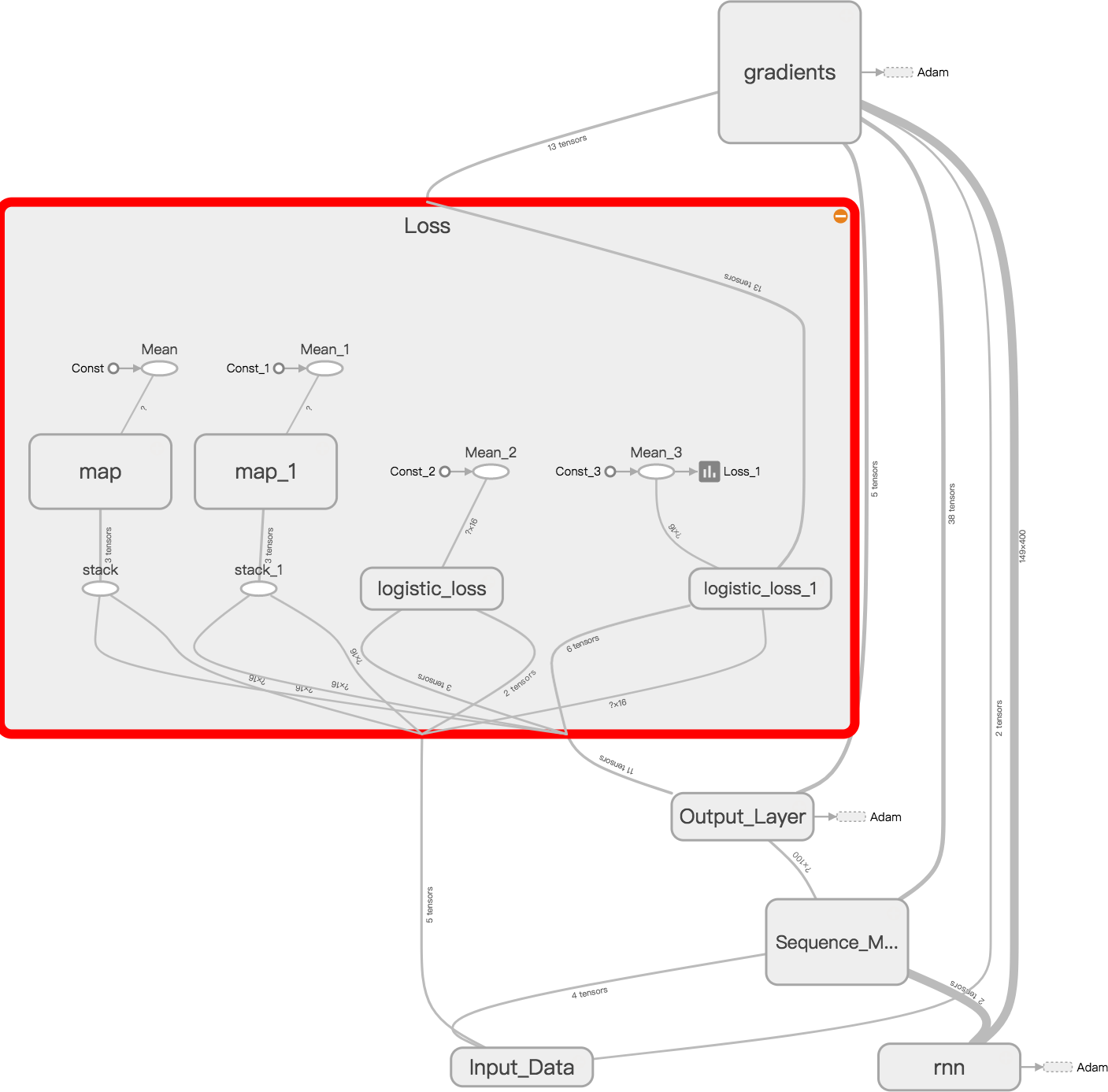
The expression lambda x, y: tf.someloss(x, y) adds three extra nodes for x, y and tf.someloss(x, y) to the graph which are not used at all when computing the gradient. To see it more clearly, one can highlight the input traces of the gradients node.
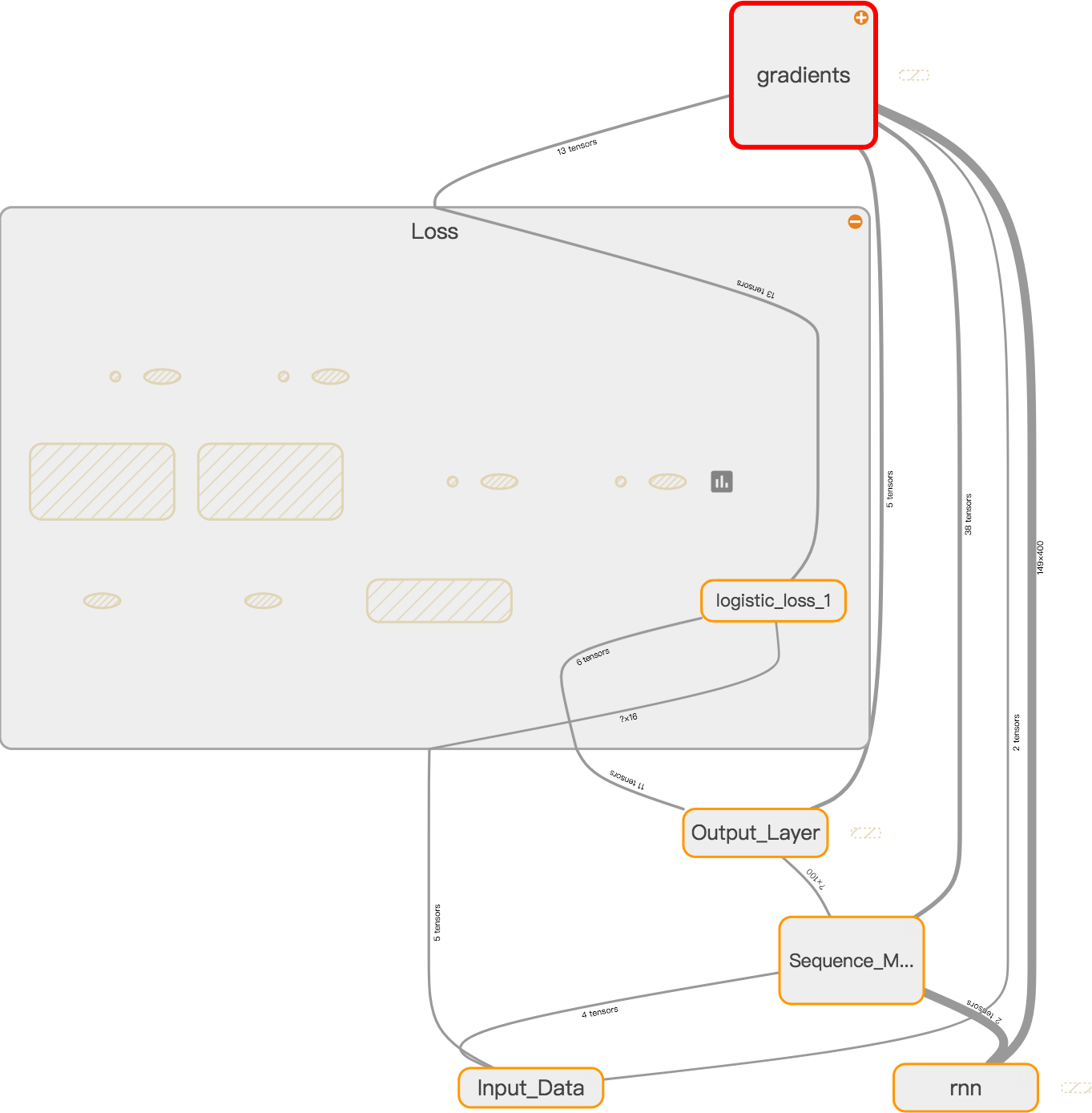
One can observe that, only logistic_loss_1 is connected to the gradients node. The other three nodes are completely useless while training. After I refactored the code by removing unnecessary lambda expressions, the GPU utilization grows to 70%. A significant speedup can be observed. What about the remaining 30%? Did I give up on that and let it go? Of course not, but it is a story for another day.
Conclusion
Having done my last project with Scala, I kind of into the functional programming and sugar-code in Scala. The mistakes above may not happen in the first place if some one follows the Pythonic way of programming. But hey, life is more fun when you do some exploration. The lesson learned here is to keep the code simple and readable. When you refactor the code, always take care of the possible side-effect, especially with the computational graph in Tensorflow. In Python, the code is usually interpreted and executed line by line. In Tensorflow sess.run() is the actual starting point, meaning that there is no actual computation until sess.run() invoked. This subtle difference may cause some troubles especially for beginners.