






Generic Neural Elastic Search: From bert-as-service and Go Way Beyond
Background
Since Jan. 2019, I have started leading a team at Tencent AI Lab and working on a new system GNES (Generic Neural Elastic Search). GNES is an open-source cloud-native semantic search solution based on deep neural network. It enables large-scale index and semantic search of text-to-text, image-to-image, video-to-video, and any-to-any content form. For readers who don’t know about this project, I strongly recommend you to check it out on Github.

Unlike many AI/ML open-source projects, GNES is neither an implementation of a specific algorithm nor a collection of models. GNES has a very ambitious goal of being the next generation search engine: it aims at the generality, enabling the search of almost any content form (e.g. text, image, and video); it aims at AI-in-production, respecting the best engineering practices and being optimized for the cloud user experience.
In this post, I will talk about the key design principles behind GNES, explain to you why we develop this framework in this way and at this time. I would also like to share our understanding of a generic information retrieval system to the AI/ML/NLP/CV community, and how it might differ from the conventional search system. Right now GNES is still under heavy developments and fast iterations, it will keep in this way for the next months. I hope this post could draw some attention from the community, encouraging more AI researchers and engineers to join us and make GNES even better.
Table of Content
- Foreword: Few Thoughts on AI Innovation and Engineering
- GNES Preliminaries: Breakdown of Neural, Elastic and Search
- GNES Design Philosophy
- GNES as a Team
Foreword: Few Thoughts on AI Innovation and Engineering
In this section, I want to pass along a few thoughts about AI innovation, engineering and open-source. They seem to be irrelevant to our theme, but they implicitly affect how GNES is designed and positioned in the market.
I have talked about most of the content in this section publicly in AAIC 2019, the 2nd annual meeting of GCAAI, the New Stack podcast and internally at Tencent. If you were the audience of these events, feel free to skip this section.
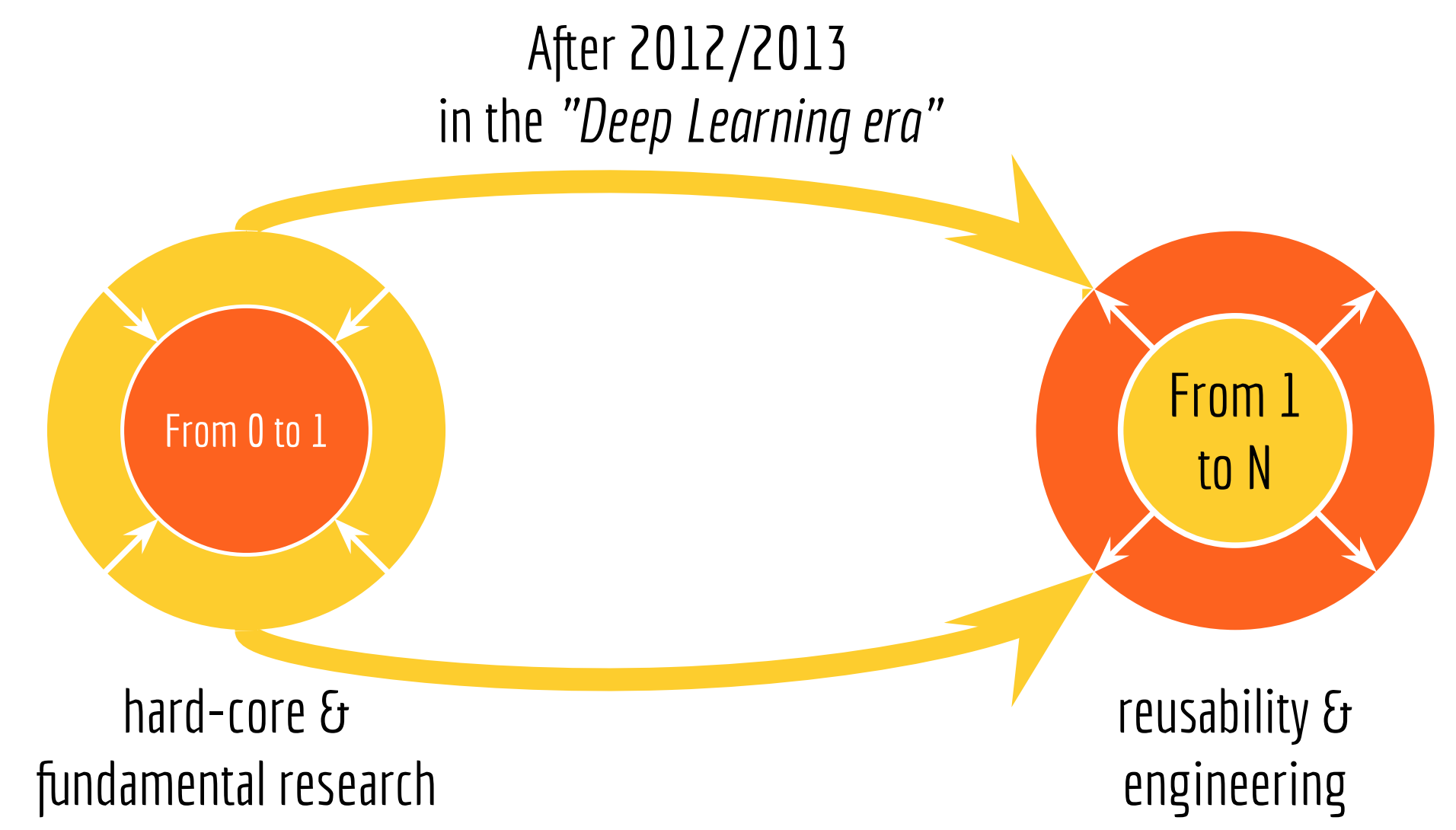
- There are two types of innovation on AI: from 0 to 1 and from 1 to N. In the deep learning era, people are moving away from the zero-to-one and join the one-to-N innovation.
- Forget about training! It is not (economically) feasible anymore.
- An effective way of contributing to today’s AI community is focusing on an end-to-end application.
You can also fast forward to the next section if the ideas above are boring to you.
1. There are two types of innovation on AI: from 0 to 1 and from 1 to N. In the deep learning era, people are moving away from the zero-to-one and join the one-to-N innovation.
I always see the progress in AI from two aspects:
- From 0 to 1. Zero-to-one is all about hard-core and fundamental research, e.g. new learning and training paradigms, new computing infrastructure and new hardware architecture.
- From 1 to N. One-to-N focuses more on usability and engineering. Problems such as adapting an algorithm from one domain to multiple domains; serving a model to billions of users; improving existing user experience with AI algorithms; piping a set of algorithms to automize the workflow; all of them belong to the one-to-N innovation.
Before 2012 (I call it the pre deep learning era), zero-to-one innovation was quite popular. People debated the best way to utilize data for problem-solving. Decision forests, margin-based approaches, kernel methods, graphical models, parametric and non-parametric Bayesian models, neural network; each data-driven method is backed by some supporters. They keep iterating and improving the methodology until it outperforms the peers in the benchmark. Deep neural network was also in this party, though not the buzziest at that time, it was showing off quite a bit.
Things have changed since 2013. As deep neural networks have been recognized by more and more researchers and engineers, people have realized that deep learning is not just a hype, it can solve many complicated problems with a much higher accuracy comparing to the traditional “shallow learning”. As we are standing now in 2019, one can argue that deep learning is the defacto solution of many AI applications, e.g. image classification, machine translation, speech recognition.
Having agreed on the methodology, many moves away from the zero-to-one and join the party of one-to-N innovation (including myself). Nowadays, deep neural networks such as CNN and RNN have been widely used as the backbone of many AI-powered features in everyday-product, such as facial payment, voice assistants, automatic customer service and K12 education.
Impact on GNES: I consider GNES as a one-to-N type of contribution to the community. It focuses on AI-in-production and puts reusability, flexibility, and scalability as the priority.
2. Forget about training! It is not (economically) feasible anymore.
The idea of forget about training could be pretty radical to many machine learning engineers. A model without training, do you mean throwing a randomly initialized model into production? Of course not. To be fair, I am talking about forgetting about training from scratch (but I intentionally remove the last part of the sentence to make the statement strong).
To elaborate, there are four typical steps in the traditional machine learning workflow: preprocessing, training, evaluating and serving. They are usually accomplished by one (e.g. a DevOps team) or two teams (e.g. data scientists + software engineers) in the company. However, the increasing training cost of a good model has changed this organization structure, producing a gap between training and serving.
To see that more clearly, we can compare the training cost of AlexNet (the first popular DNN based image classification algorithm in 2012) to AlphaZero (a DNN reinforcement learning-based Go-player in 2018). According to this blog post from OpenAI, the training cost has increased from 0.0058 petaflop/s-day to 1,700 petaflop/s-day, that is 300,000x in only six years! Meanwhile, the training cost of Google BERT (a bidirectional transformer model that redefined the state of the art for 11 natural language processing tasks) is $6,912; and GPT-2 (a large language model recently developed by OpenAI which can generate realistic paragraphs of text) takes $256 per hour for training. And that does not count in bad initializations or data errors, which often require a re-training.
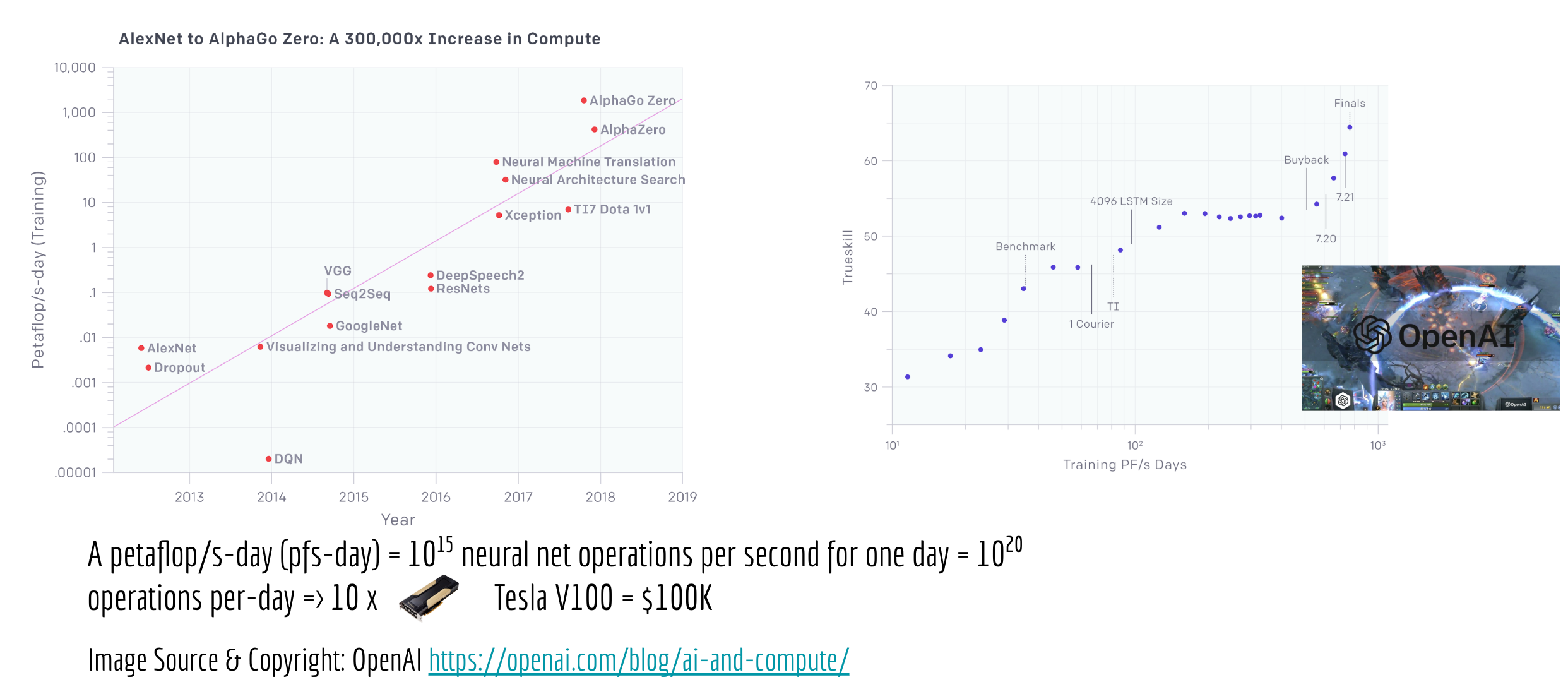
For small companies and startups who focus on AI applications, these numbers could be quite scary, not to mention the extra time spent on trial-and-error and the money spent on retaining the best AI talents. But even in the big tech giants, it is not economically feasible for everyone, only a small number of teams can afford to train such high-profile models from scratch. Sometimes the teams don’t have the scalable infrastructure, other times it is considered risky from a project management perspective.
Apart from the economic reason, from the machine learning perspective, it is also counter-intuitive to train models repetitively from scratch on every new task, especially when these tasks share the same low-level information. For example, in NLP tasks such as news classification and sentiment analysis, the low-level knowledge of the language (e.g. grammar, the meaning of individual words) remains constant. In CV tasks such as object recognition and autonomous driving, there is no need to re-learn common concepts such as colors, textures, and reflections from task to task.
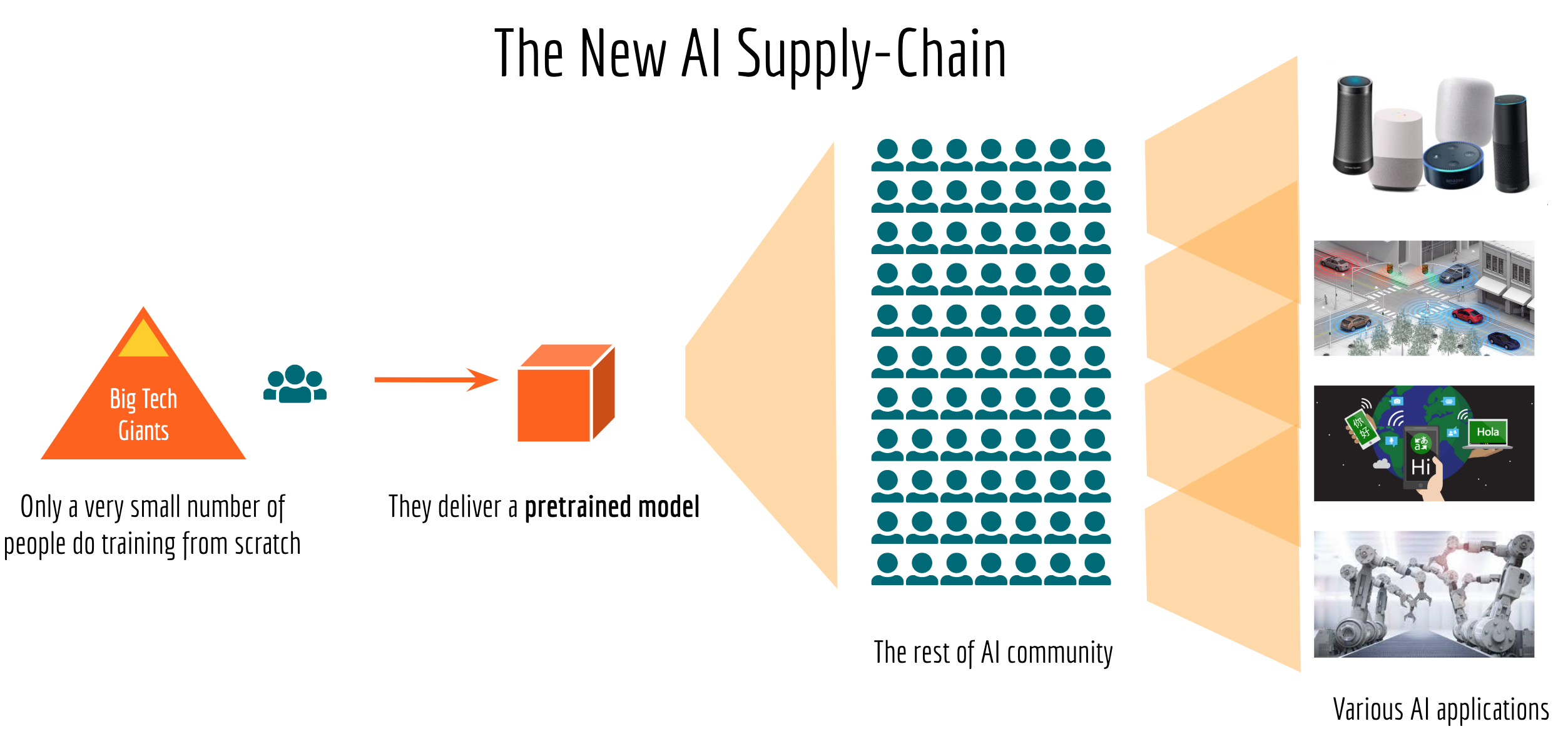
That being said, it should be easy to understand the emerging AI supply-chain: only a very small number of people in the world will work on training new models from scratch, they deliver a “pretrained model” to the rest of the AI community. Most of AI engineers will then try to make sense of this pretrained model by adapting it to their applications, fine-tuning based on their data, incorporating domain knowledge to it and scaling it to serve millions of customers. The image above illustrates this new AI supply-chain.
Impact on GNES: The architecture behind GNES is optimized for inference, namely how to effectively deliver prediction results to users/developers. In GNES, we have a design philosophy of “model as a docker, docker as a plugin“. That is, every pretrained model is wrapped in a docker container, and this container is used as a plugin to GNES framework. Although GNES supports partial training/fine-tuning, it is not the main focus for now.
3. An effective way of contributing to today’s AI community is focusing on an end-to-end application.
If you feel a bit upset after reading through the first two points, believing there is nothing you can contribute to the AI community unless you are in big tech giants or sufficient economic incentive exists; then you shouldn’t. Let’s look at the pyramid below which partitions the AI development landscape into three layers:
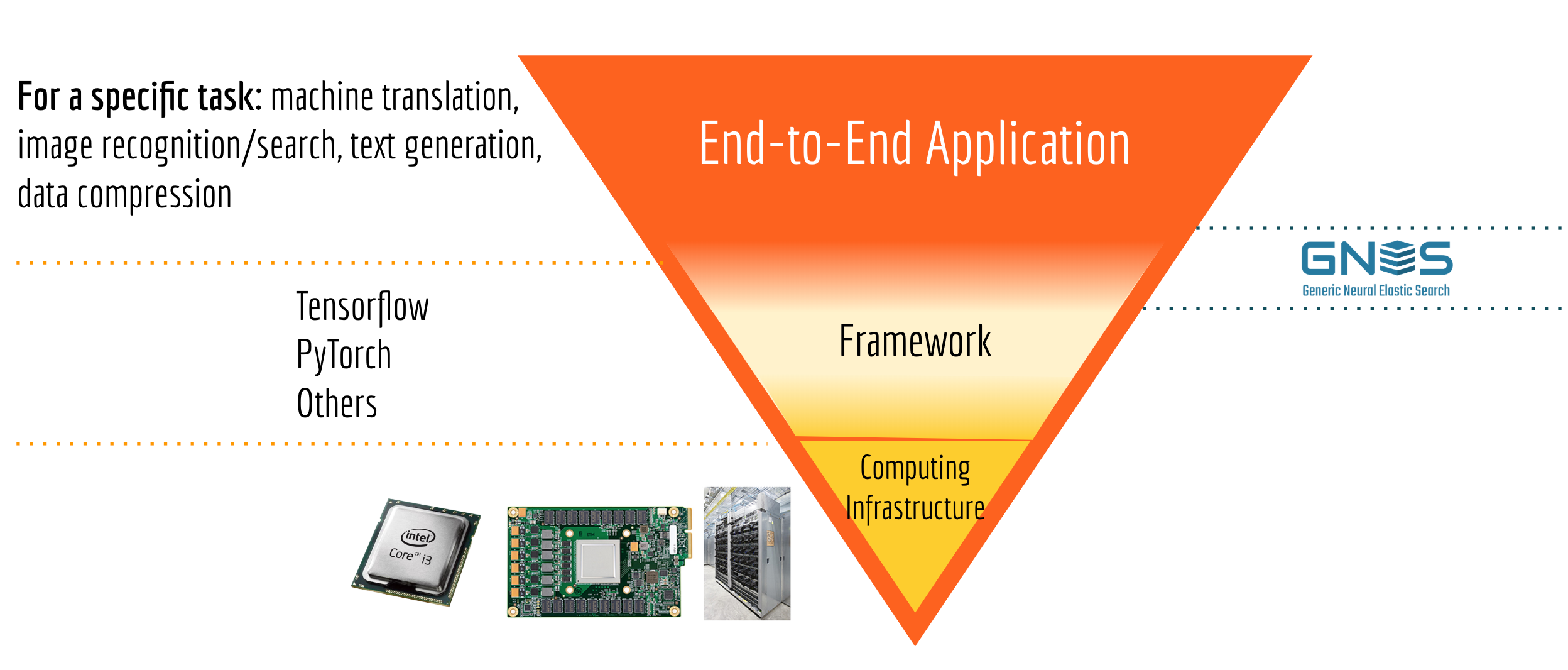
On the bottom, we have computing infrastructures, including CPU, GPU, FPGA, edge device, cloud computing, etc. There are a lot of progress and opportunities in this layer, especially as AI algorithms now deploying to everywhere (e.g. on your phone, in your fridge) the need for computing everywhere is quite demanding. However, advancing the computing infrastructure is not easy, both technical-wise and capital-wise it has a very high bar for just entering the competition. For startups, individuals or AI enthusiasts, I don’t think this is a realistic way to contribute.
The middle layer is AI frameworks. For most of AI developers/engineers, frameworks are their primary interface to the low-level hardware. Needless to say, there is huge market value in the framework layer: whoever dominates the framework market can reshape the AI dev-community and possibly affect the AI R&D direction in general. As we are standing now in 2019, one has to admit that Tensorflow (including Keras) and Pytorch dominate the framework market. As a comparison, it was a completely different landscape four years ago in 2015. If you could ask the question “what do you use for deep learning?” back in time, you would get very diverse answers such as Matlab, Mathematica, Theano, Caffe, Deeplearning4j, OpenNN, which now play very minor roles in today’s AI development. Though we still see new framework emerging from time to time, my understanding is that outperforming Tensorflow and Pytorch to grab a share of this red ocean market is extremely challenging.
Finally, the top layer is the vast end-to-end AI applications. There we have a lot of opportunities to make significant contributions, by leveraging the mature deep learning frameworks and off-the-shelf pretrained models. Asking your colleagues or friends the question “which AI package do you use for facial recognition/machine translation/image enhancement?”, you would most likely get “I’m not sure” or different answers from person to person. This is often an indicator that the market is still uncontested, and there is ample opportunity for growth and building a community around it.
Impact on GNES: GNES is positioned in the intersection area between the framework layer and end-to-end application layer, as illustrated in the last figure. On the one hand, it delivers an end-to-end search solution to users. On the other hand, it is also an extremely flexible and elastic framework that allows developers to implement more features on top of it.
GNES Preliminaries: Breakdown of Neural, Elastic and Search
To understand why GNES is designed in this way, one has to first understand how a standard neural search system works, which I will talk about first. I also assume you have basic knowledge of deep neural networks and representation learning, models like BERT, XLNet, VGG, AlexNet should not be alien names to you.
GNES has three runtimes: training, indexing, and querying.
The first concept I’d like to introduce is the runtime. In a typical search system, there are two fundamental tasks: indexing and querying. Indexing is storing the documents, querying is searching the documents on a given query, pretty straightforward. In a neural search system, one may also face another task: training, where one fine-tunes the model according to the data distribution to achieve better search relevance. These three tasks: indexing, querying, and training are what we call three runtimes in GNES. In the sequel, when talking about the system workflow, I will always specify the runtime it works in.
Now let’s consider the following pipeline consists of an encoder and an indexer. In the index runtime, the encoder transforms all documents (text, image, video, audio) into fixed-length vector representations $\{d_1, d_2, \ldots, d_n\,|\,d_i\in\mathbb{R}^D\}$, then the indexer stores all these vectors in a database that allows fast-access. In the query runtime, the encoder transforms a given query to a vector $q$, and looking for its top-k neighbours that are most similar to $q$, i.e. $\arg\max_{i\in{1,\ldots, n}} \mathrm{sim}(d_i, q)$.
A good neural search is only possible when document and query are comparable semantic units.
Despite being vague on the actual choice of encoder, indexer and similarity metric, the aforementioned pipeline should be quite straightforward to understand and intuitively could give you meaningful results. However, in practice, this pipeline only works in very limited scenarios. To be specific, this pipeline only makes sense if the query and the indexed document are comparable semantic units. For example, when the query and document are both sentences between 10 to 20 words, or when the query and document images are more or less in the same size. Otherwise, it will fail.
It fails not because of a bad encoder you choose, but because there is no encoder can embed arbitrary large information into a fixed-length vector. Like it or not, each encoder has an intrinsic optimal size it can handle, which depends on the deep neural network architecture, the training data, the atomic NN ops (e.g. the kernel and stride in conv2d) used. This optimal size is what I call the optimum semantic unit, documents/queries that are significantly smaller or larger than this size would degenerate the encoder’s performance, and yield a bad search result. The next picture illustrates this concept.
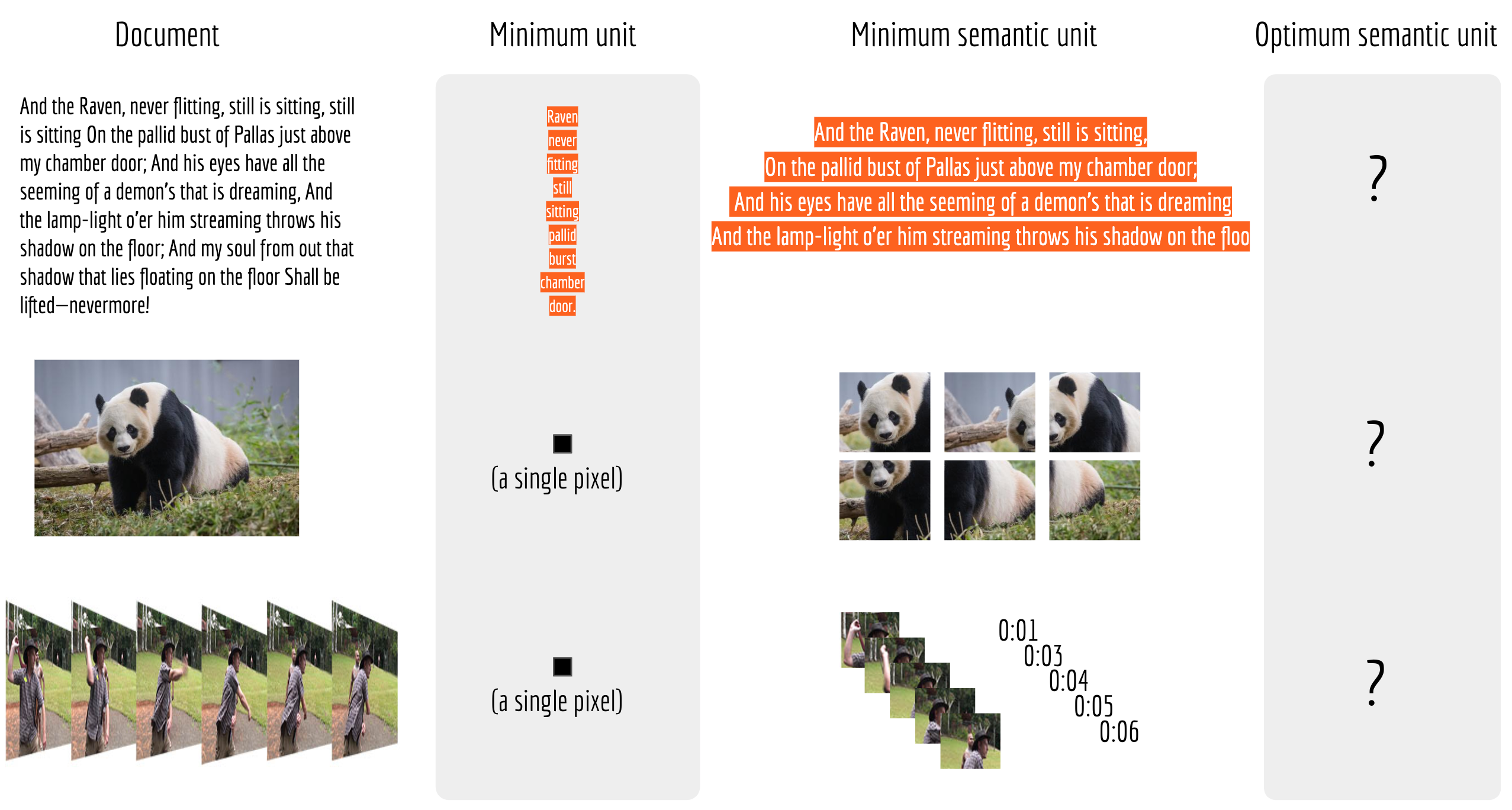
In anyways, one should not expect that feeding a minimum unit to the encoder could yield any meaningful embedding. For most use cases, we have a good prior knowledge of the reasonable semantic unit, e.g. sentences split by [,.!?] in NLP, 32$\times$32 patches extracted a large image in CV. Finally, I leave the optimum semantic unit of each modality as a question mark, for the reasons that the optimum semantic unit often depends on the underlying encoder and the application.
To solve the problem of mismatched semantic units between query and document, we introduce a preprocessor module in GNES. In the index runtime, the preprocessor first segments a document into a set of chunks $D=\{c_1, c_2, \ldots, c_d\}$, each of which corresponds to a reasonable semantic unit. These chunks are then encoded and stored in a database. In the query runtime, the preprocessor segments the query into chunks again $Q=\{k_1, k_2, \ldots, k_q\}$, encoder embeds chunks into vectors and indexer searches for nearest chunks with their corresponding document IDs. Finally, a score is computed by taking the chunk weights, chunk-chunk relevances, document weights into account. More precisely,
$$P(Q, D) \propto \sum_{c_i\in D} \sum_{k_j\in Q} \underbrace{P(c_i, k_j)}_{\text{\tiny from indexer, computed}}\times\overbrace{P(c_i|D)}^{\text{\tiny from indexer, stored}}\times \underbrace{P(k_j|Q)}_{\text{\tiny from preprocessor}} \times\overbrace{P(D)}^{\text{\tiny{from indexer, predefined}}}$$
A complete sequential workflow should look like the following:
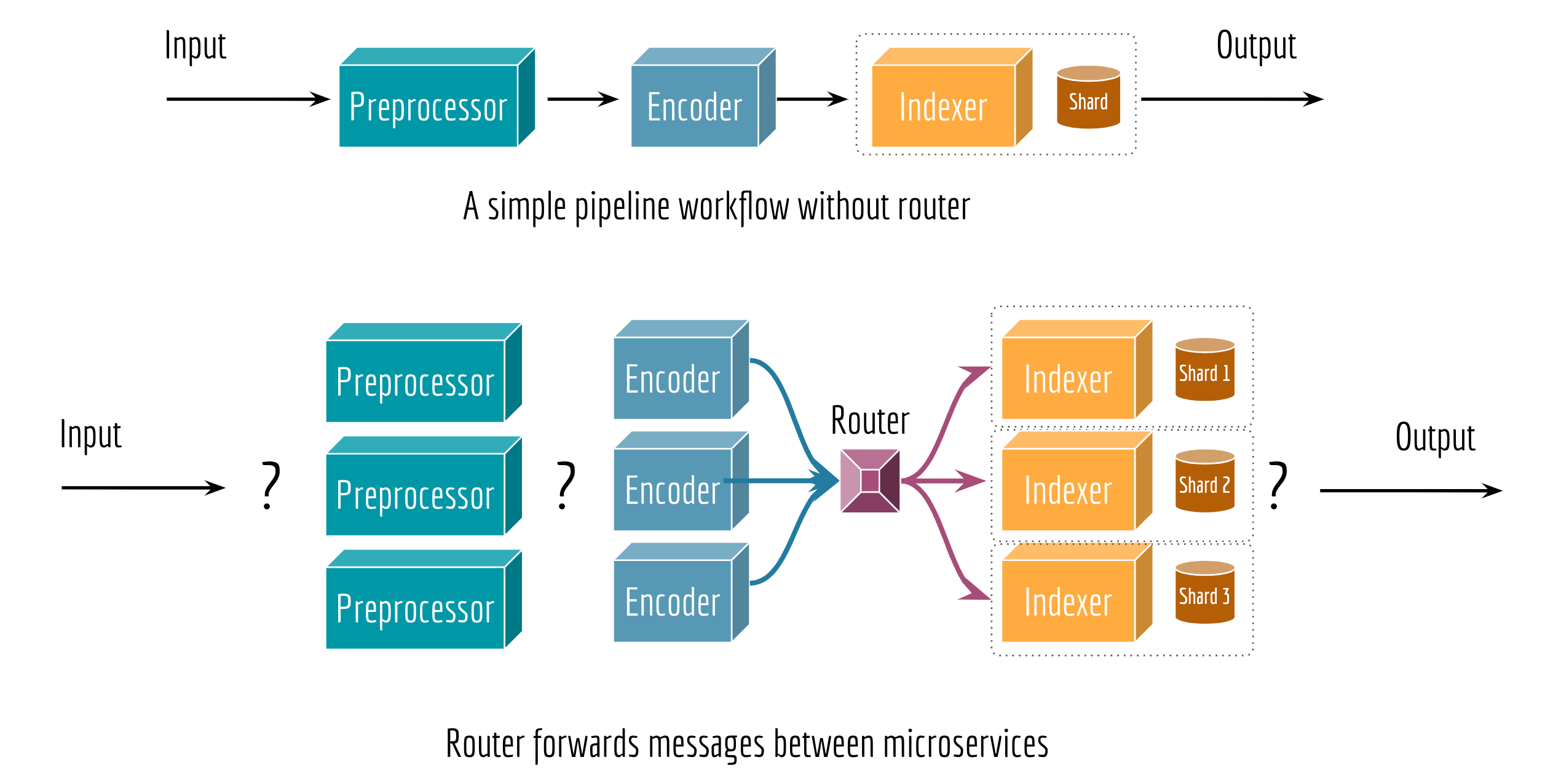
Routers are required for building an elastic system.
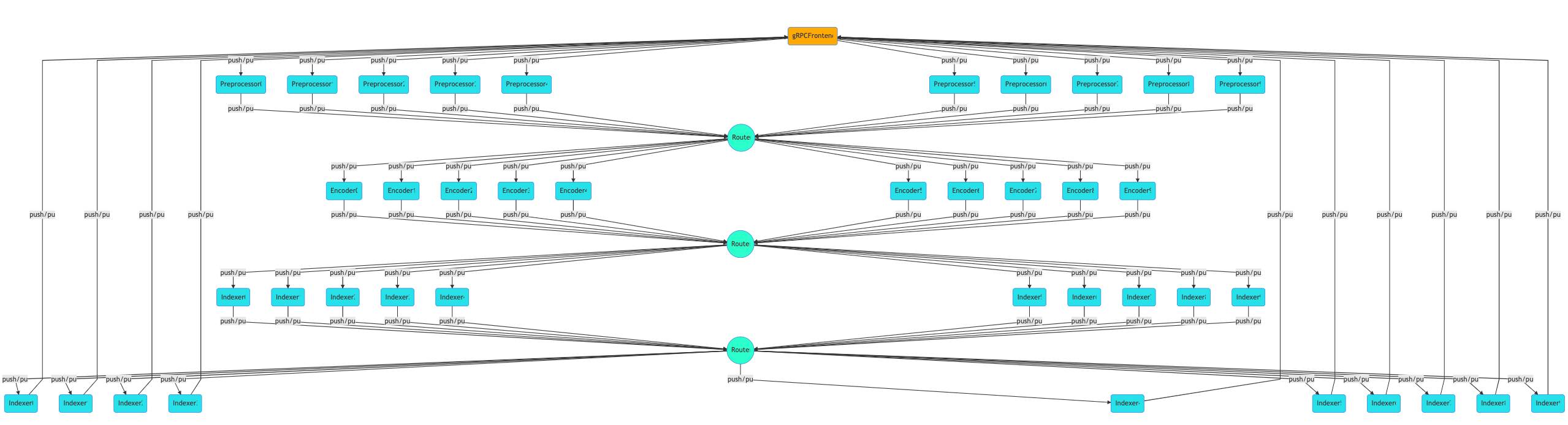
As our goal is to scale up the whole workflow by allowing an arbitrary number of preprocessors, encoders, and indexers at each step, we need a router to correctly forward messages between steps. The behavior of a router depends on the topology of the workflow and the runtime. Sometimes a router serves as a mapper, splitting a message into multiple parts; other times it serves as a reducer or an aggregator. The type of a router can often be determined by the two consecutive steps, it may not be required in some corner cases.
GNES has four fundamental components: preprocessor, encoder, indexer and router. Each runs as an independent microservice.
To summarize, we have four fundamental components in GNES:
- Preprocessor: transforming a real-world object to a list of workable semantic units;
- Encoder: representing a semantic unit with vector representation;
- Indexer: storing the vectors into memory/disk that allows fast-access;
- Router: forwarding messages between microservices: e.g. batching, mapping, reducing.
In GNES, these components are running independently as microservices. For machine learning engineers and data scientists who are not familiar with the concept of cloud-native and microservice, one can picture a microservice as an app (on your smartphone). Each app can be independently installed, launched and deleted. To accomplish a task, (e.g. take a selfie, beautify it then post it on Facebook), you have to coordinate multiple apps working together.
GNES Design Philosophy
Now that you have learned all the fundamental concepts of GNES, I would like to talk about the key tenets of GNES. Please note that the following content is not served as the documentation of GNES, it may be vague on how GNES work internally.
A Cloud-Native System
I never believe that a monolith program can serve in production, especially for the search scenario. Unlike many canonical monolithic deep learning packages, GNES is born to be cloud-native. From the very beginning, we have structured GNES as a collection of decoupled components (e.g. preprocessor, encoder, indexer, router), each of which can then be deployed, scaled and maintained independently. In GNES, each component is running as a stateless microservice in its own isolated Docker container. They follow a welldefined and narrowly-scoped API: read the incoming message, do something about it, and pass it to the next (microservice).
Note that the data layer is isolated between components in GNES: each component may have its own datastore and scaling characteristics and storage technology. For instance, some encoders may need to mount a file system for loading pretrained models, whereas some indexers might employ NoSQL databases. Multiple indexer services may also share the database with a simple configuration. Either way, the components have complete autonomy.
In the example below, we start with a simple GNES workflow for indexing. In particular, we want to index both the original documents and encoded vectors in parallel. The table below summarized the GNES YAML config we are using and the corresponding network topology (figure on the right is rendered by GNES Board):
| 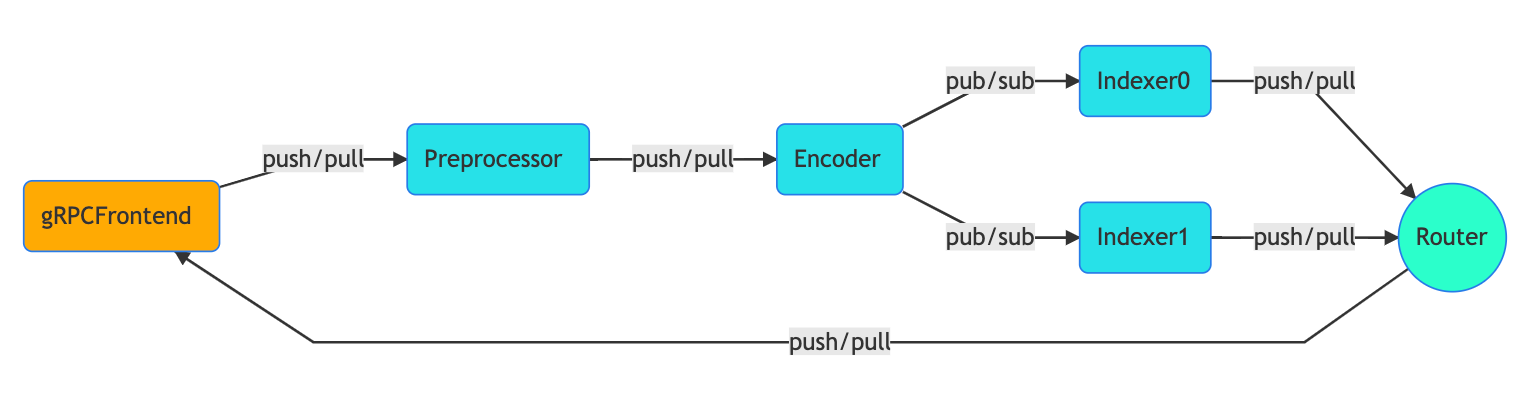 |
Then scaling it to:
| 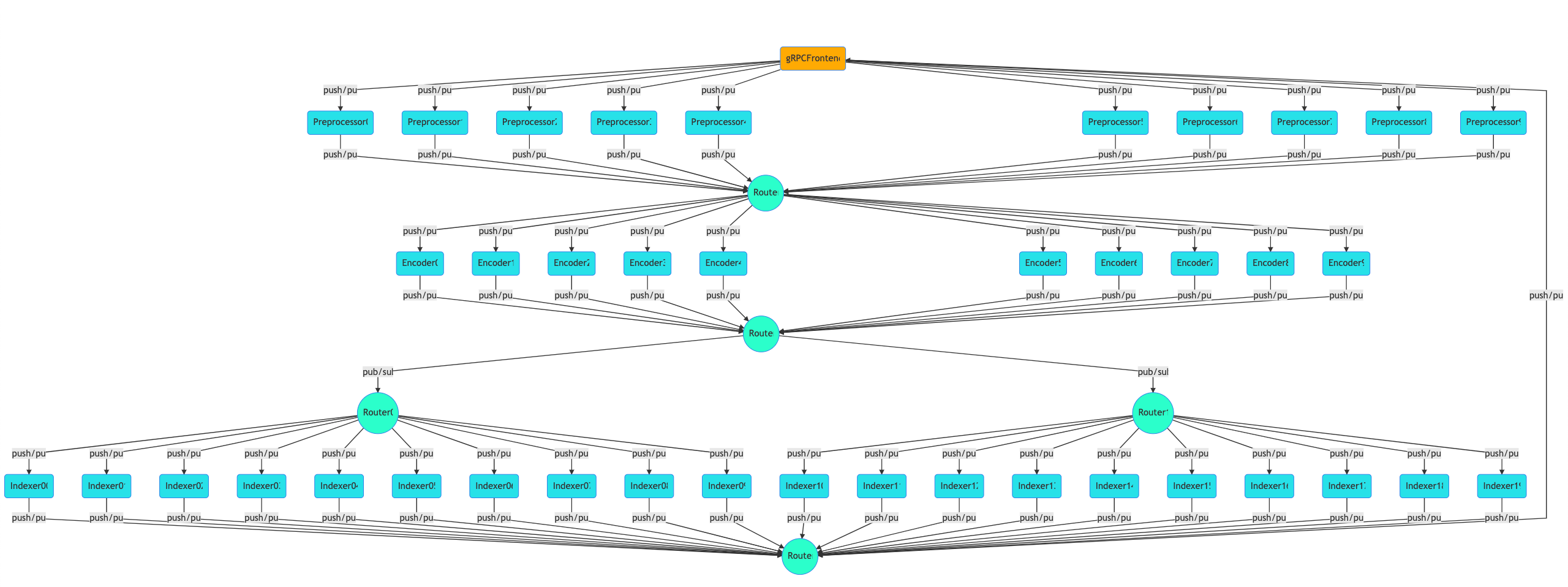 |
Notice how routers are automatically added to the stack. And without changing the logic of any component, one can switch the whole stack to the query mode by simply changing the YAML config to:
|  |
, where we search document IDs using the chunk embeddings first (via a vector-indexer defined in vector.yml), then fill in the documents with their original content (via a key-value indexer defined in full-text.yml).
Of course, in order to coordinate all microservices and maximize cloud’s advantage, we need some orchestration technology such as Docker Swarm and Kubernetes. To that, we developed GNES Board, an interactive web interface allowing one to modify GNES architecture and immediately get the corresponding Docker Swarm or Kubernetes deploy solution.
Model as Docker, and Docker as a Plugin
After the release of Google BERT model and my followed bert-as-service in late 2018, the NLP community has put the research of pretrained language model on the fast-lane. People have proposed dozens of improved BERT models since then: some supports longer sentences, some outperforms the original BERT on various NLP tasks. From time to time, one frequent question I was often asked by the community is: “Han, can you support model X and make it X-as-a-service?”
This makes me wonder if bert-as-service has a sustainable architecture, in which rapidly changing requirements can be met by constantly adding new models to it, not modifying (and breaking) old ones.
Frankly, I sometimes feel quite challenging to keep up with today’s AI development: new models pop up every week, refreshing the leaderboard, nagging you to give it a try. However, refactoring or porting the new model implementations into GNES framework can be time-consuming and not very cost-effective. Not to mention GNES covers algorithms from NLP, CV, database, etc. I’m also aware of some deep learning packages that attempt to incorporate as many models as they can, but I don’t think they can last long.
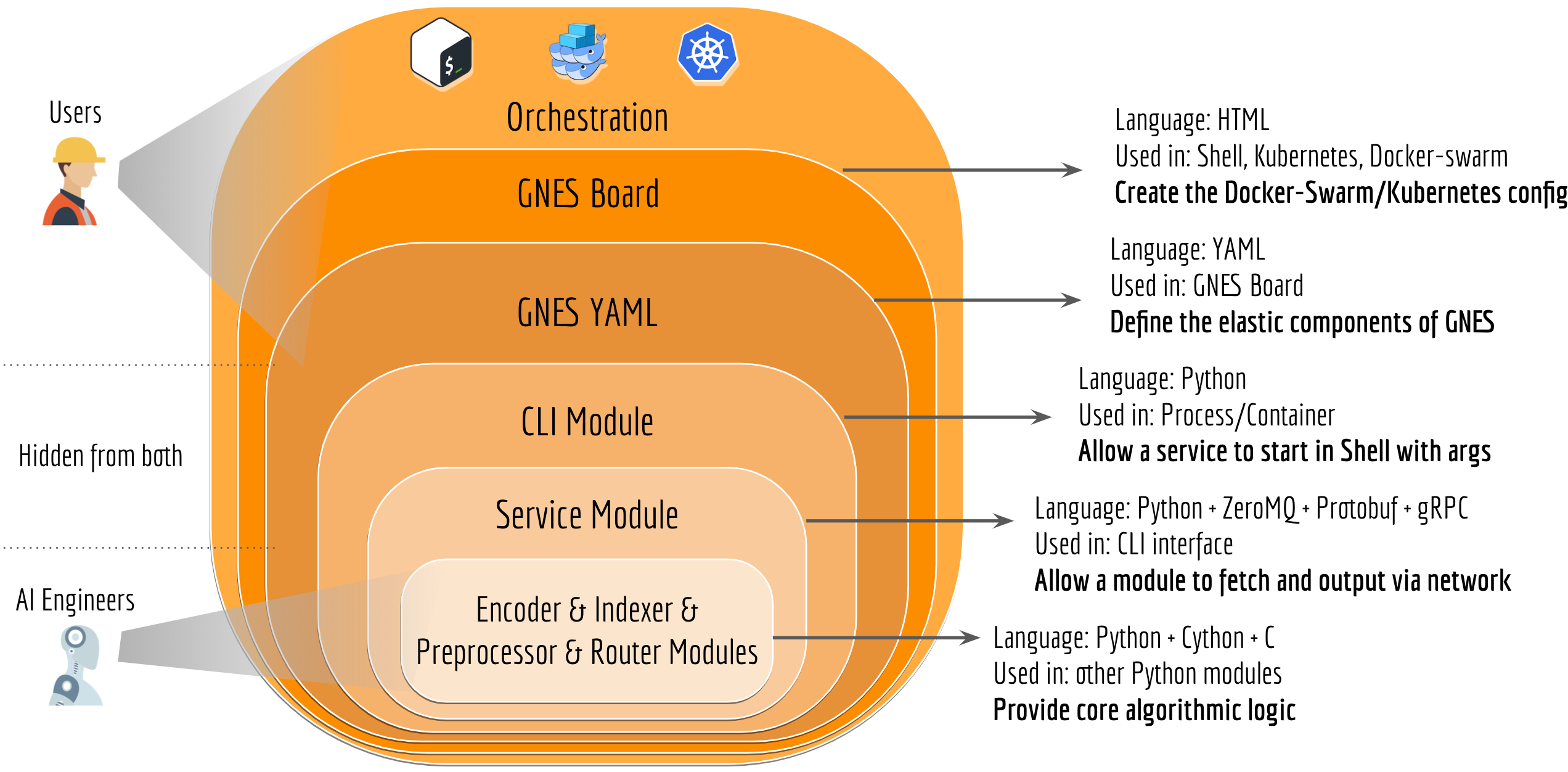
Therefore, the scope of GNES component, aka. the service boundary must be clearly defined.
Let’s first look at what an algorithm usually requires to run/reuse:
- dependencies: packages or libraries required to run the algorithm, e.g.
ffmpeg,libcuda,tensorflow; - codes: the implementation of the logic, can be written in Python, C, Java, Scala with the help of Tensorflow, Pytorch, etc;
- a small config file: the arguments abstracted from the logic for better flexibility during training and inference. For example,
batch_size,index_strategy, andmodel_path; - big data files: the serialization of the model structure the learned parameters, e.g. a pretrained VGG/BERT model.
In practice, it is extremely hard to manage all four pieces in an organized way. For example, some dependencies can not be installed via packaging tools like pip, and others must be first compiled and then make install. Meanwhile, the data file could be so big and you have to set up a separate AWS S3 bucket storing them and then do wget/curl as initialization. Did I mention CDN, MD5 checksum and version control on the data file? You get the idea: it is hard.
Model as Docker (container), and Docker as a plugin. This is the GNES solution in the face of accelerating innovation on new models from the AI community.
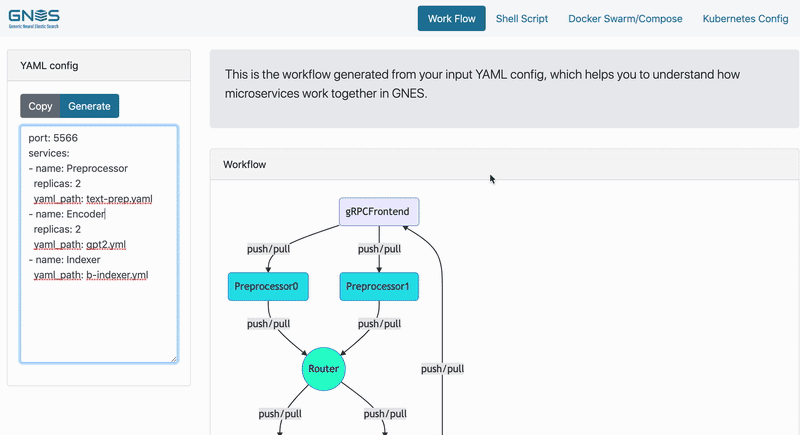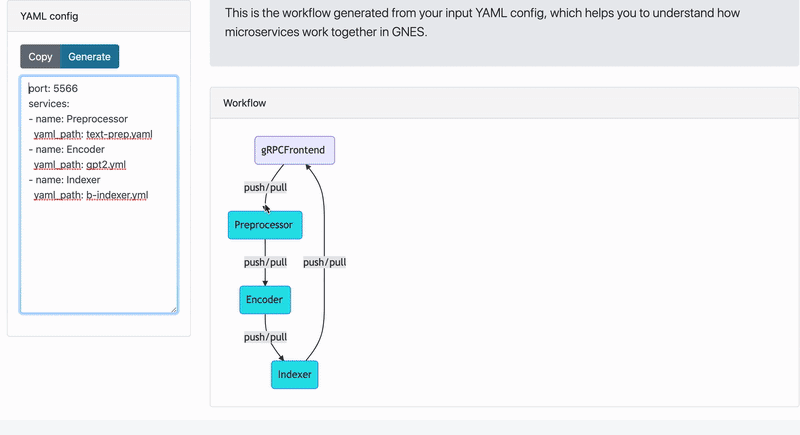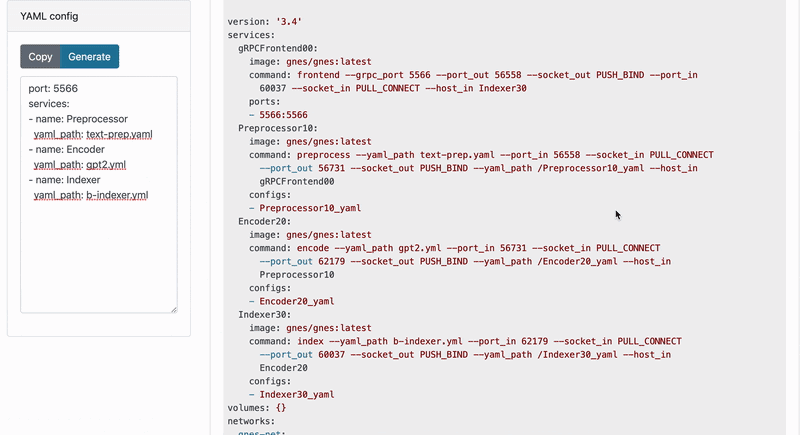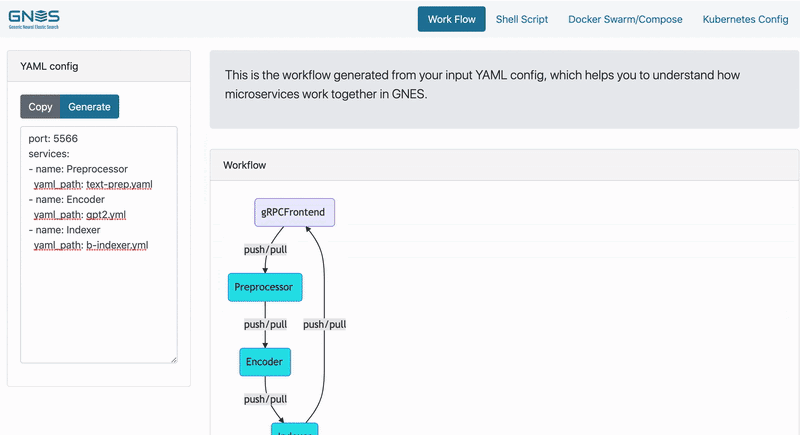
In GNES, changing a component is as simple as changing a line of config. The best part is, GNES allows one to change a component on different levels: on the container level, on the GNES YAML, or the component-wise YAML. For example, at the highest container level, changing the preprocessor and the encoder is done by simply modify the generated Docker Swarm config (i.e. a docker compose file) from this:
1 | version: '3.4' |
to this:
1 | version: '3.4' |
For AI engineers who want to contribute a new model, GNES provides an extremely straightforward interface in Python. One only needs to write a Python class with an accompanied YAML file. All other things like service, network communication, containerization, don’t you worry about them. They are all abstracted away from this interface and handled by GNES automatically. Let’s see the following example, where I build a dummy text encoder called FooContribEncoder:
dummy_model.py | dummy_model.yml | ||||
|---|---|---|---|---|---|
|
|
Likewise, one can implement its preprocessor, indexer and router. The next figure illustrates the abstraction and design in GNES. It enables AI engineers/developers to focus all of their development efforts on writing the logic of the algorithm, without a full understanding of the entire GNES system upfront, which can take an extraordinarily long period time to achieve.
Generic and Universal
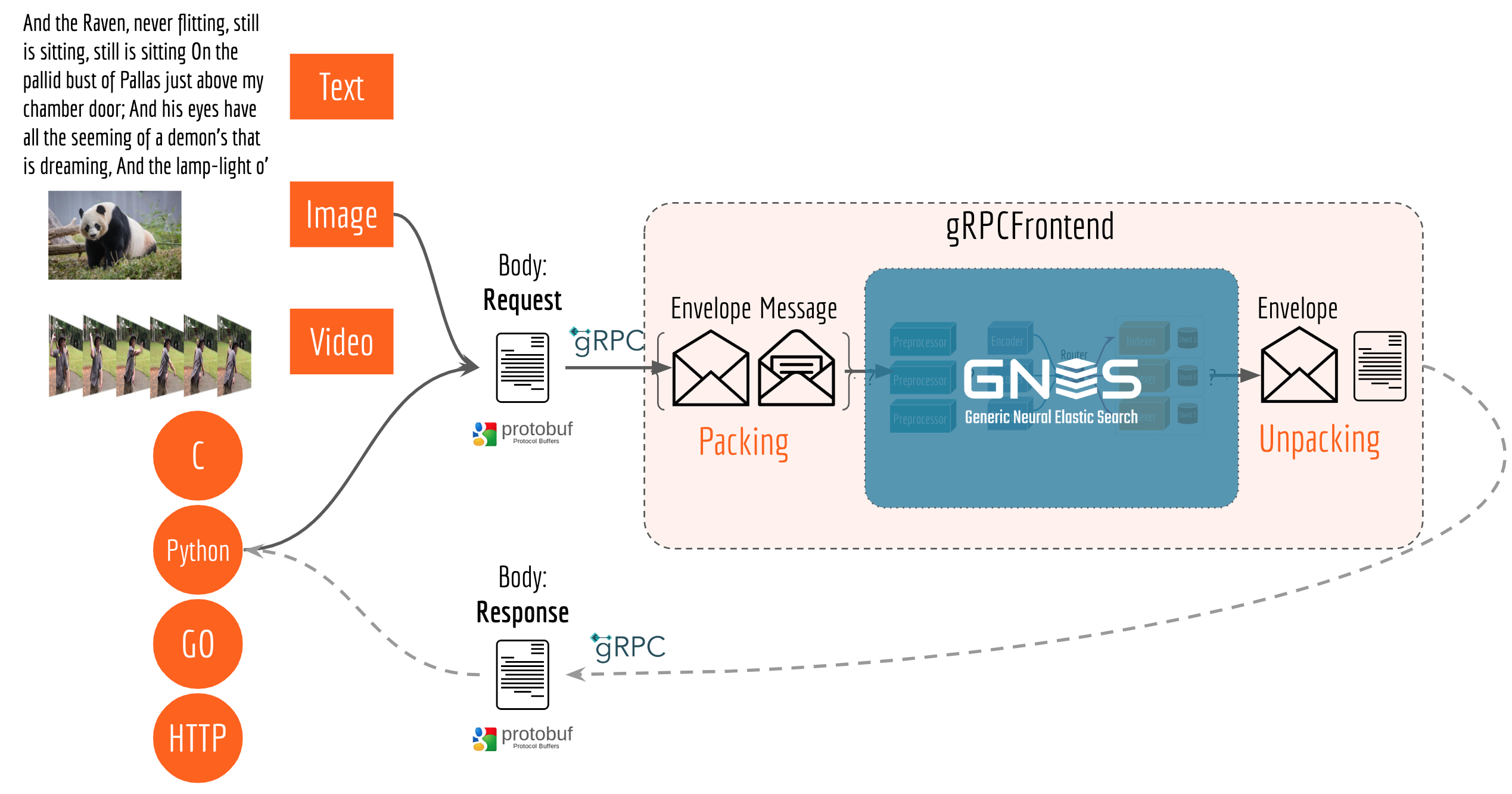
One lesson I learned from developing bert-as-service is that one should make the interface as universal as possible so that more people can use it via their favorite programming languages. In GNES, we employ Protocol Buffers and gRPC in the very early stage of interface design. In particular, we make a clean separation between the information the end-user requires (body) and the information that the system requires (envelope). The next table summarized the protobuf design.
Protobuf: Message | Protobuf: Envelope | ||||
|---|---|---|---|---|---|
|
|
To end-users, the interface is simply request and response. They don’t have to know what envelope looks like. The table below summarizes the protobuf design of request and response.
|
|
When a user sends a request, gRPCFrontend first packs the message within an envelope, including all information that the core GNES components need. Each component then opens the envelope, reads/modifies the message, adds a stamp to the envelope, and passes to the next component. Finally, before sending the response back to the user, gRPCFrontend unpacks the message from the envelope and returns the response to the user. The complete message passing procedure is depicted in the next figure.
GNES as a Team
Any organization that designs a system (defined broadly) will produce a design whose structure is a copy of the organization’s communication structure.

As the final remark, I want to talk about the team behind GNES. Frankly, this is the first time I lead a team of five full-timely building an AI project from scratch. In the past few months, there are a lot of funs, tears and of course growths. In fact, the experience of building GNES refreshes my understanding of Conway’s law, which I probably will share in another post. In general, building an open-source software inside a big company is actually not easy, harder than many people thought. Aligning the business interests and community’s interests is tricky, and as the founder of GNES there are many things I have to take care of and plan ahead besides writing code. Anyways, there are two tenets that I always ask my teammates to follow:
Making No Tech Debt
Nobody likes tech debt, but everyone makes it, especially under business pressures. In the early days of GNES, I did spend some effort into setting up a healthy development environment inside the team. This includes code lint, commit and PR protocols, meeting and releasing schedules, test coverage, and the DevOps cycle. These “cultural” things seem irrelevant to what the AI community interested in, but over time the team gets better agility in managing the whole infrastructure and quicker adaption to the new requirements.
Having a B2D Thoughtship
B2D is the shorthand for business to developer, as the products and services we are building are marketed to other developers. Having a B2D thoughtship means always keeping the developer experience in mind and thinking in switched positions. What are the pain-points for developers? Are there confusing and ambiguous in GNES APIs? How can we better support developers who use a different tech stack? Can we provide a seamless and easy way to let developers contribute to GNES? Every day our team learns the best practices from high-quality opensource software; avoids the bad code what we as developers dislike or blame at; and gradually builds up a vivid and healthy community around GNES, which is our ultimate goal.