






New Evaluation Mode Explained in Jina v0.7
With 450 new commits from 19 contributors all over the world, we are excited to release Jina v0.7.0 today. This release comes with new features including unique indexing, support on fluentd and syslog logging, Flow visualization (which we shall see in the sequel), and Jina Hub CLI integration. One of the most exciting features among them is the new evaluation mode. It allows user to benchmark the index and search workflow against the given groundtruth, making the quality of the system assessable. In this article, I will briefly discuss how we design the evaluation in Jina v0.7.0 and the rationale of such design.
Jina is an easier way for enterprises and developers to build cross- & multi-modal neural search systems on the cloud. You can use Jina to bootstrap a text/image/video/audio search system in minutes. Give it a try:

Table of Contents
- What is Evaluation in Jina?
- Evaluation is Not a New Runtime
- Where to Read and Write Evaluation Data?
- Summary
What is Evaluation in Jina?
In general machine learning context, evaluation is about comparing the predicted result and the desired result, and then representing this difference as a number. Evaluation helps one to understand the system better: it sheds a light on tuning the parameters of the system. When it comes to a neural search system like Jina, what exactly are we expecting here?
A quick answer could be comparing the final document ranking $[d_1, d_3, d_5, d_7, \cdots]$ and the desired document ranking $[d_2, d_5, d_7, d_3, \cdots]$. Evaluation is then about assessing the alignments between these two sequences. This is a reasonable answer, however, it ignores the fact that a search system is often composed by multiple components; whereas evaluation on the final results only can hardly reveal any useful insights about the system. It is not straightforward to see the problematic component.
After all, evaluation is not the ultimate goal, it is a debugging tools, an intermediate step for improving the system. Therefore, as a debugging tool we should allow user to pinpoint at any part of the system for evaluation.
Evaluation Formulation
In Jina v0.7, evaluation is designed to work anywhere in the workflow not just at the end. Formally, say we have a full index/search flow space $\mathcal{F}$ for a certain task. Denote $\mathbf{F}\subseteq\mathcal{F}$ as subflows with all possible parameterizations. For example, $\mathbf{F}_1$ could be a simple segmenter on sentences with any configs, $\mathbf{F}_2$ could be a chain of image segmenter and CNN encoder with any configs and parameters. Moreover, $f\in\mathbf{F}_1$ is a parameterization of the subflow, e.g. a sentence splitter with delimiter configured to [,.?]. In particular, we denote $f^{\star}$ as the perfect parameterization that would give us the desired output.
Now given a request $q\in \mathcal{Q}$ defined by Jina Protobuf message, flows modify requests $f: \mathcal{Q} \rightarrow \mathcal{Q}$. Consequently, the actual output of the subflow $f$ can be written as $f(q)$ and the desired output is $f^{\star}(q)$. The evaluation function $\Delta: \mathcal{Q}\times\mathcal{Q}\rightarrow\mathbb{R}$ maps $f(q)$ and $f^{\star}(q)$ from the request space to a real-value. The next figure illustrates this idea.
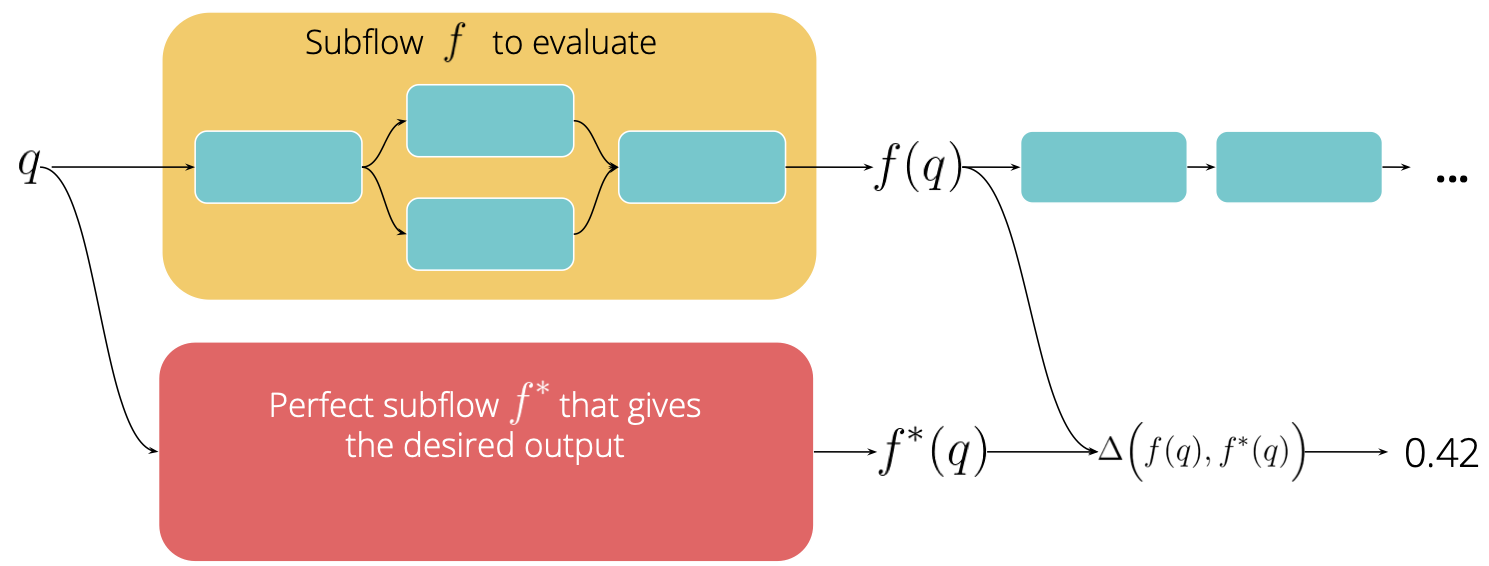
Note that the groundtruth $f^{\star}(q)$ is often directly given by users, e.g. the click-through data, the crowdsourcing labels. In a more sophisticated settings, $f^{\star}$ is an oracle/a teacher system, the output of which is considered as the groundtruth. In this case, the evaluation tells how well can our current system $f$ mimic the behavior of $f^{\star}$ on certain task.
Diff Extraction and Quantization
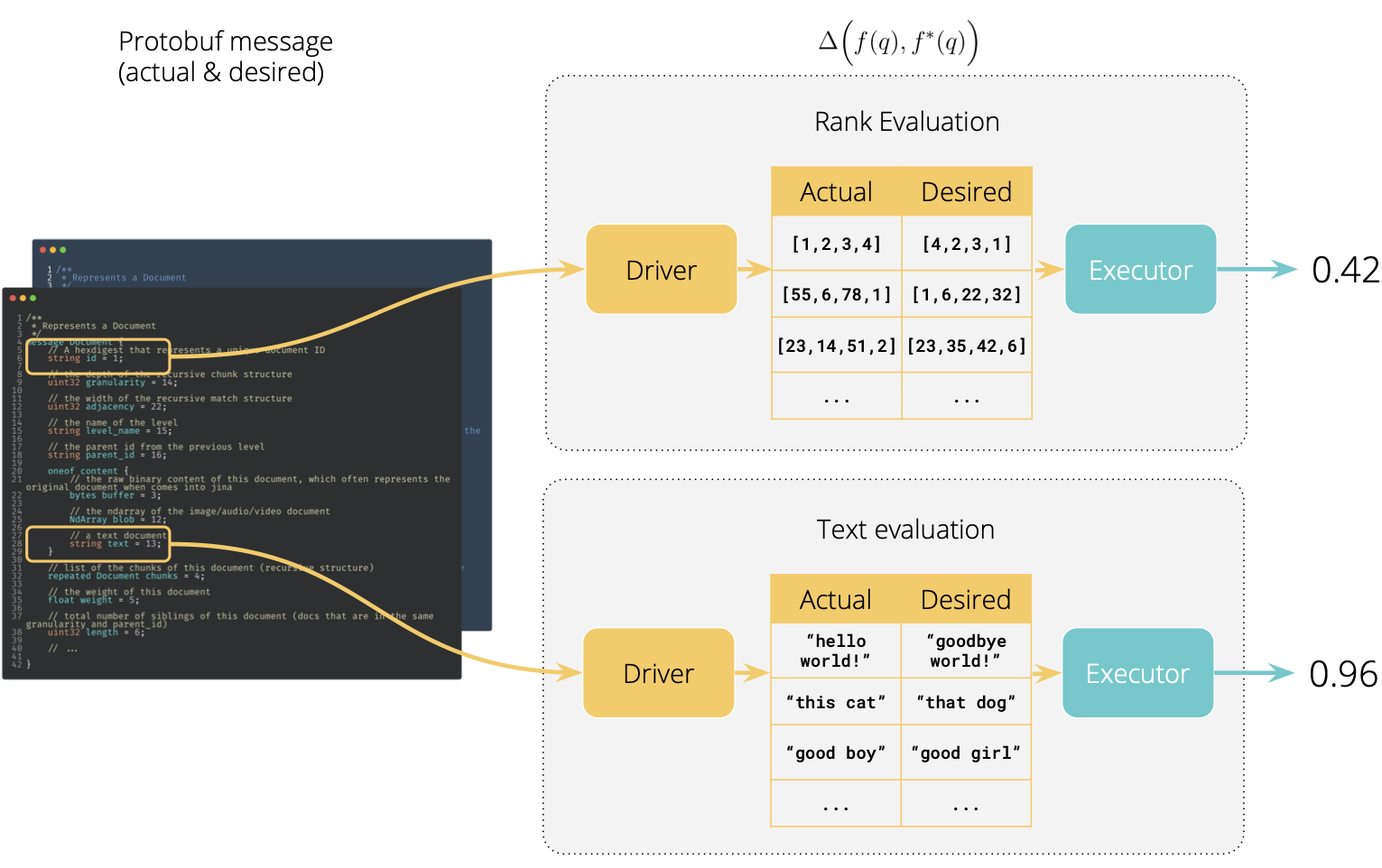
We now take a closer look at the function $\Delta$, which contains two steps:
The first step is to compute the difference between $f(q)$ and $f^{\star}(q)$. As request contains recursive
Documentstructure, it recursively looks for all the changes on numbers, strings,ndarrayand any other typed fields in the Protobuf. For example,Number difference:
1
2
3
4q_a = {1:1, 2:2, 3:3}
q_d = {1:1, 2:4, 3:3}
delta_diff(q_a, q_d)
{'[2]': {'desired_value': 4, 'actual_value': 2}}String difference
1
2
3
4q_a = {"a":"hello", "b":"world"}
q_d = {"a":"goodbye", "b":"world"}
delta_diff(q_a, q_d)
{ "['a']": { 'desired_value': 'hello', 'actual_value': 'goodbye'}}Set difference
1
2
3
4q_a = {5, 6, 7}
q_d = {6, 7}
delta_diff(q_a, q_d)
{ "set_item_added": [5]}
The second step is to quantitize the diffed object to a number. These scoring functions are often data type/task-specific. The table below summarizes the frequently used functions.
| Evaluation field | Scoring function |
|---|---|
doc.text | Edit distance, Rouge-L, BLEU1,2,3,4 |
doc.embedding | Euclidean distance, Cosine similarity, L1-Norm, Infinite-Norm. |
doc.matches.id[] | Spearman’s correlation, Precision@K, Recall@K, F1@K, MRR |
Users of Jina may immediately realize that these two steps correspond perfectly to the Driver & Executor abstraction layers in Jina. In fact, this is exactly how we implement evaluation in v0.7. The first step, extracting the diff information from Protobuf, is done by the BaseEvaluationDriver. Multiple inheritances are implemented to extract from different types of field. The second step, computing the evaluation metric is done at the BaseEvaluator(BaseExecutor), which is Protobuf-agnostic. The figure below illustrates this idea.
Training Formulation
Finally, though out of the scope of this post, we can formulate the training task in Jina as finding the optimal flow $\hat{f}$ such that,
$$\hat{f} := \arg\min_{f\in\mathcal{F}} \sum_{q\in\mathcal{Q}}\Delta\Big(f(q), f^{\star}(q)\Big)$$
Evaluation is Not a New Runtime
In my previous post, I mentioned that a neural search system has three runtimes: training, indexing and searching. So is evaluation the fourth runtime? We had this discussion internally and our initial implementation was on this direction: we added a new EvaluateRequest in protobuf and all executors respond to this new EvaluateRequest by binding to the correct drivers. However, we quickly realize the flaw of such design: from low-level Driver to high-level Flow, each layer has to define its behavior under this new runtime. This added complexity is never justified.
Evaluation should work like a thermometer, one can pinpoint and take measurement regardless the runtime of the system. Just like a real-world thermometer, one can measure the temperature while jogging, sleeping or eating. You never say, “okay body, I’m going to measure your temperature, so please ask all your cells to standby and change into the correct mode.” Thermometer does not work in this way, neither does your body.
We follow this mindset in v0.7: evaluation works in parallel with IndexRequest and SearchRequest. The new Flow API .inspect() allows one to add evaluation Pod at arbitrary place in the Flow without worrying about its runtime,
1 | from jina.flow import Flow |
1 | f = (Flow(inspect='HANG') |
1 | f = (Flow(inspect='HANG') |
Zero Side-Effect to Flow
One highlight of .inspect() is that it does not introduce any side-effect to the flow:
- The evaluations are running as “side task” in parallel. They deviate from the main task and are not required to complete the request. Thus, it won’t slow down the flow on the main task.
- Attaching an inspect Pod to the flow does not change the socket type between the original Pod and its neighbours.
- All inspect Pods can be removed from the Flow by setting
Flow(inspect='REMOVE'). The table visualizes three choices ofinspectparameter:
with Flow(inspect='COLLECT'): (default) |
|---|
with Flow(inspect='HANG'): |
with Flow(inspect='REMOVE'): |
Where to Read and Write Evaluation Data?
Finally, let’s talk about IO of evaluation: where should one read the groundtruth and where to write the evaluation results. In Jina v0.7 we provide two ways to put groundtruth data:
- Directly in the Protobuf. both
IndexRequestandSearchRequestprovide a new fieldrepeated Document groundtruths. The Flow-level data ingest APIFlow.index()andFlow.search()will check if the fed data comes in a tuple of two: if yes, then the first element is used as input and the second element is used as the groundtruth. Groundtruth input in this way will be carried over the network. All the pods in the flow, no matter where they are, can read fromRequest.groundtruths. - Load via
EvaluateExecutor. By leveragingKVIndexerone can load groundtruths data matching toDocument.id. Groundtruth data load in this way are only available to this Pod (and the sequel Flow). This is particular useful when the groundtruth data is big and should not be sent over the network.
The evaluation results is written to Document.evaluations in Protobuf, a list of NamedScore defined at Document level. A document can have multiple evaluation metrics at the same time, e.g. precision, recall and F1. By default, all evaluations are gathered and grouped by the Document ID.
Summary
Enabling evaluation is an important milestone for Jina. Not only it allows one to assess the quality of a workflow, but also shed a light on training Jina effectively.
Besides that, there are hundreds of patches in v0.7 adding new features, improving scalability, and making Jina more easy-to-use. The number of contributors to Jina has increased to 72. We feel very fortunate to have the open-source community on our side and keep the momentum going strong on the development of Jina. If you want to know more about our engineering roadmap and the rationale behind specific features, welcome to join our monthly Engineering All Hands in Public via Zoom or Youtube live stream. If you want to join us as a full-time AI / Backend / Frontend developer, please submit your CV to our job portal. Let’s build the next neural search ecosystem together!