From Then to Now: a Curated List for Neural Search and Jina
Since 2017 I have been working on the neural search in different teams: Zalando Research (2014-2017), Tencent AI Lab (2018-2020), and now at Jina AI we are building the neural search ecosystem in opensource. Over the years, I explored quite a few ideas about neural search: from its core algorithms to the high-level system design, from a very academic-oriented prototype to a production-ready system. Readers can find those traces in my previous posts. These exploration and lessons-learned are incredibly valuable as they make what Jina is today.
In this post, I collect the most featured soundbites from my earlier posts and group them into different categories. If you are new to neural search, or want to understand the design principle behind Jina, this curated list would be a perfect starting point.
Jina is an easier way for enterprises and developers to build cross- & multi-modal neural search systems on the cloud. You can use it to bootstrap a text/image/video/audio search system in minutes. Check out Github and give it a try:

Table of Contents
- Philosophy on AI Engineering
- System Design
- What is Symbolic Search System?
- What is Neural IR System?
- Symbolic vs. Neural Search System
- Reading Comprehension in Search System
- The Duality in Question Answering System
- Sequence Encoding as a Service
- Bert-as-service Architecture
- Training, Indexing, and Querying in a Neural Search System
- Jina is “Tensorflow” for Search
- Jina is Not an One-Liner
- Implementing the Right Feature at the Right Layer
- Representation Learning
- Production Ready
Philosophy on AI Engineering
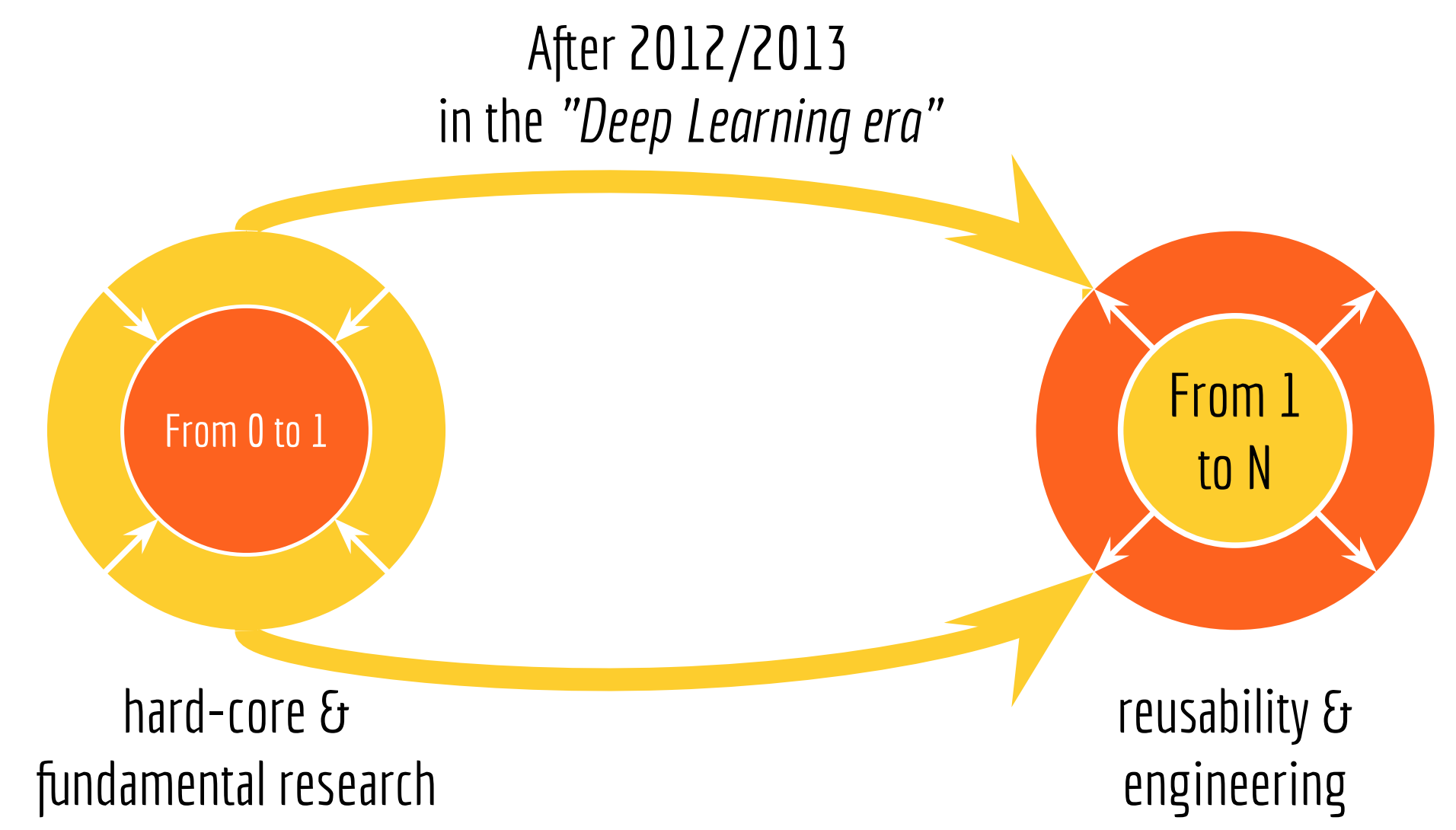
From 0 to 1, and From 1 to N
- From 0 to 1. Zero-to-one is all about hard-core and fundamental research, e.g. new learning and training paradigms, new computing infrastructure and new hardware architecture.
- From 1 to N. One-to-N focuses more on usability and engineering. Problems such as adapting an algorithm from one domain to multiple domains; serving a model to billions of users; improving existing user experience with AI algorithms; piping a set of algorithms to automize the workflow; all of them belong to the one-to-N innovation.
Forget about Training
Forget about training! It is not (economically) feasible anymore.
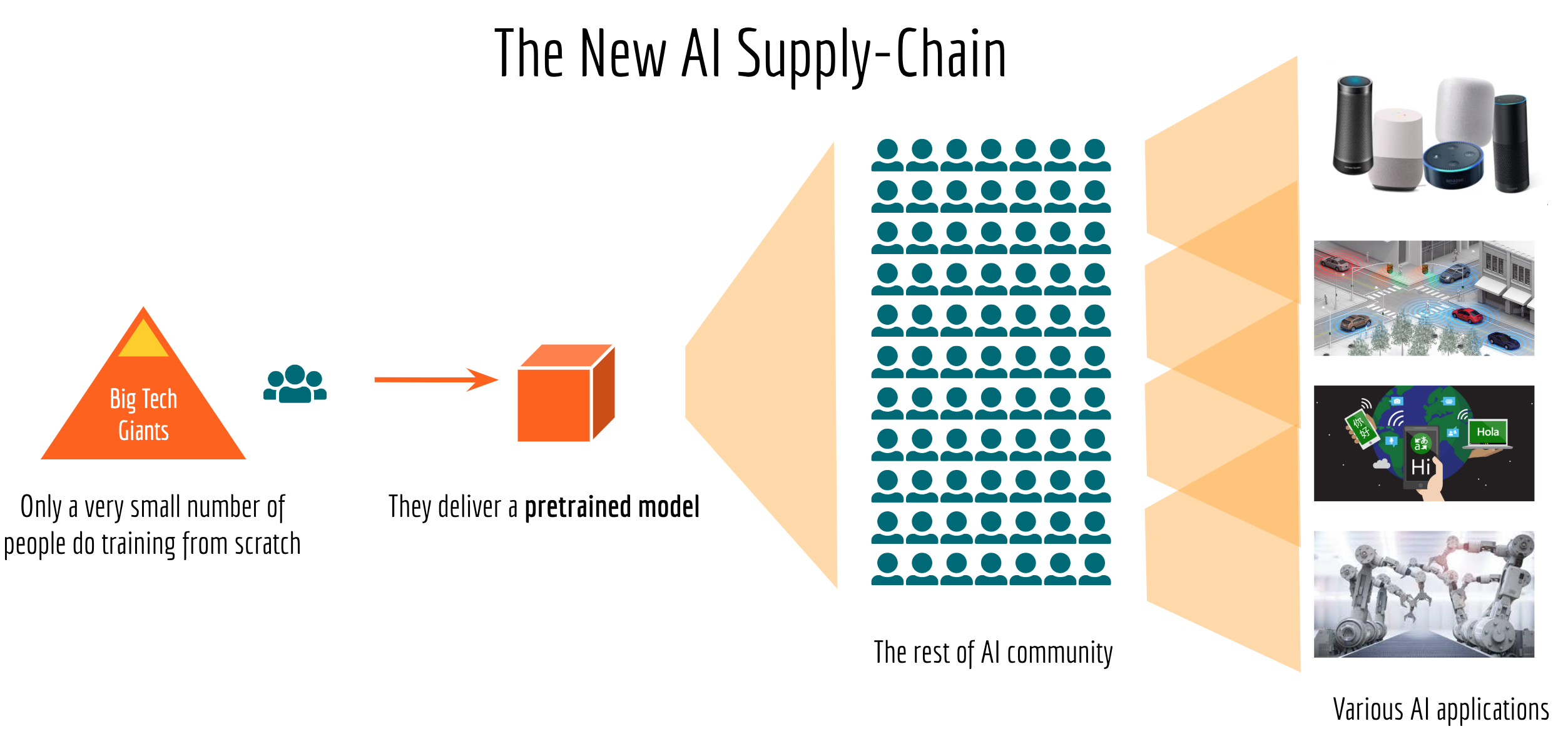
The New AI Supply-Chain
… the emerging AI supply-chain: only a very small number of people in the world will work on training new models from scratch, they deliver a “pretrained model” to the rest of the AI community. Most of AI engineers will then try to make sense of this pretrained model by adapting it to their applications, fine-tuning based on their data, incorporating domain knowledge to it and scaling it to serve millions of customers.
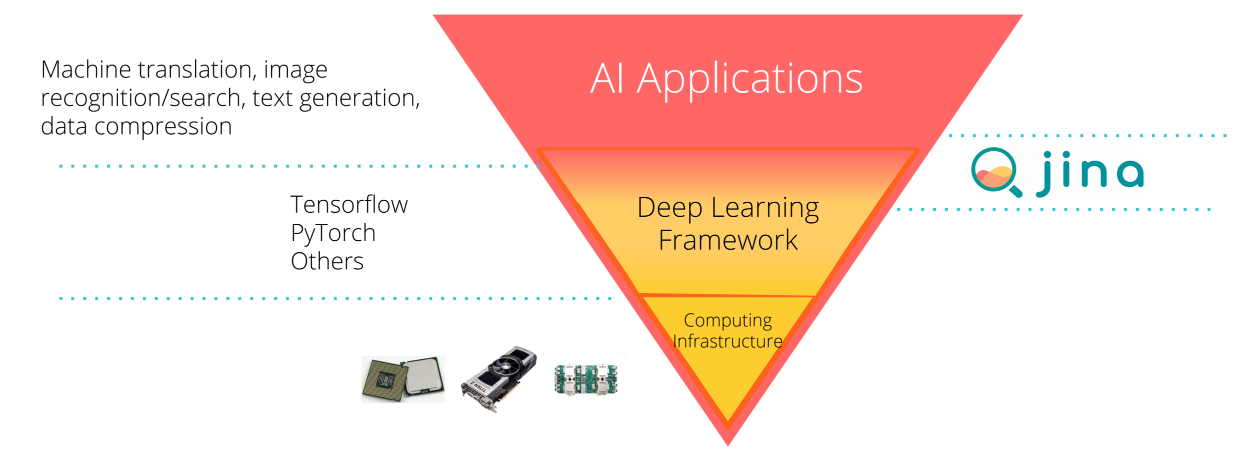
The Three-Layer Pyramid of AI Engineering
Let’s look at the pyramid below which partitions the AI development landscape into three layers:
On the bottom, we have computing infrastructures, including CPU, GPU, FPGA, edge device, cloud computing, etc.
The middle layer is AI frameworks. For most of AI developers/engineers, frameworks are their primary interface to the low-level hardware.
Finally, the top layer is the vast end-to-end AI applications.
Having a B2D Mindset
B2D is the shorthand for business to developer, as the products and services we are building are marketed to other developers. Having a B2D thoughtship means always keeping the developer experience in mind and thinking in switched positions.
Community Want vs. What We Build
The community often wants to get things done as quickly as possible. While the framework developers share the same ultimate goal, they have to take steps by first building lower layers steadily and robustly. When developing the framework as an open-source project, aligning the community expectation and being transparent on the roadmap is crucial.
System Design
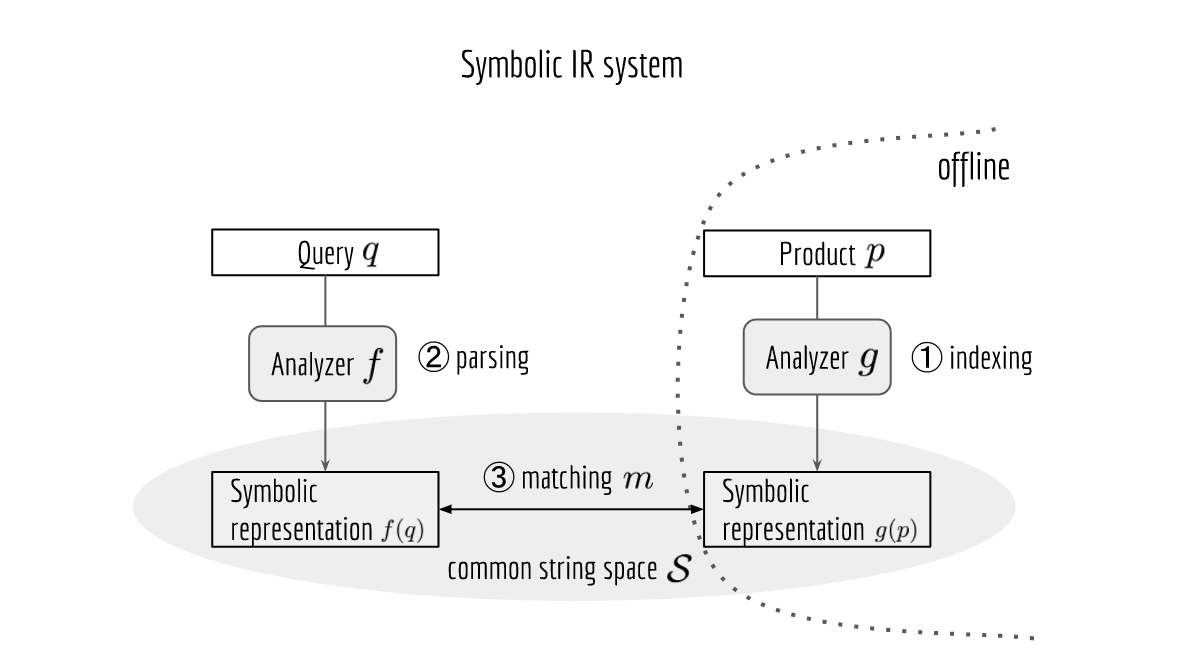
What is Symbolic Search System?
… at the core, Solr/Elasticsearch is a symbolic IR system that relies on the effective string representation of the query and product. …
Formally, given a query $q\in \mathcal{Q}$ and a product $p\in\mathcal{P}$, one can think the NLP pipeline as a predefined function that maps from $\mathcal{Q}$ or $\mathcal{P}$ to a common string space $\mathcal{S}$, i.e. $f: \mathcal{Q}\mapsto \mathcal{S}$ or $g: \mathcal{P}\mapsto \mathcal{S}$, respectively. For the matching task, we just need a metric $m: \mathcal{S} \times \mathcal{S} \mapsto [0, +\infty)$ and then evaluate $m\left(f(q),g(p)\right)$, …
What is Neural IR System?
The next figure illustrates a neural information retrieval framework, which looks pretty much the same as its symbolic counterpart, except that the NLP pipeline is replaced by a deep neural network and the matching job is done in a learned common space. Now $f$ serves as a query encoder, $g$ serves as a product encoder.
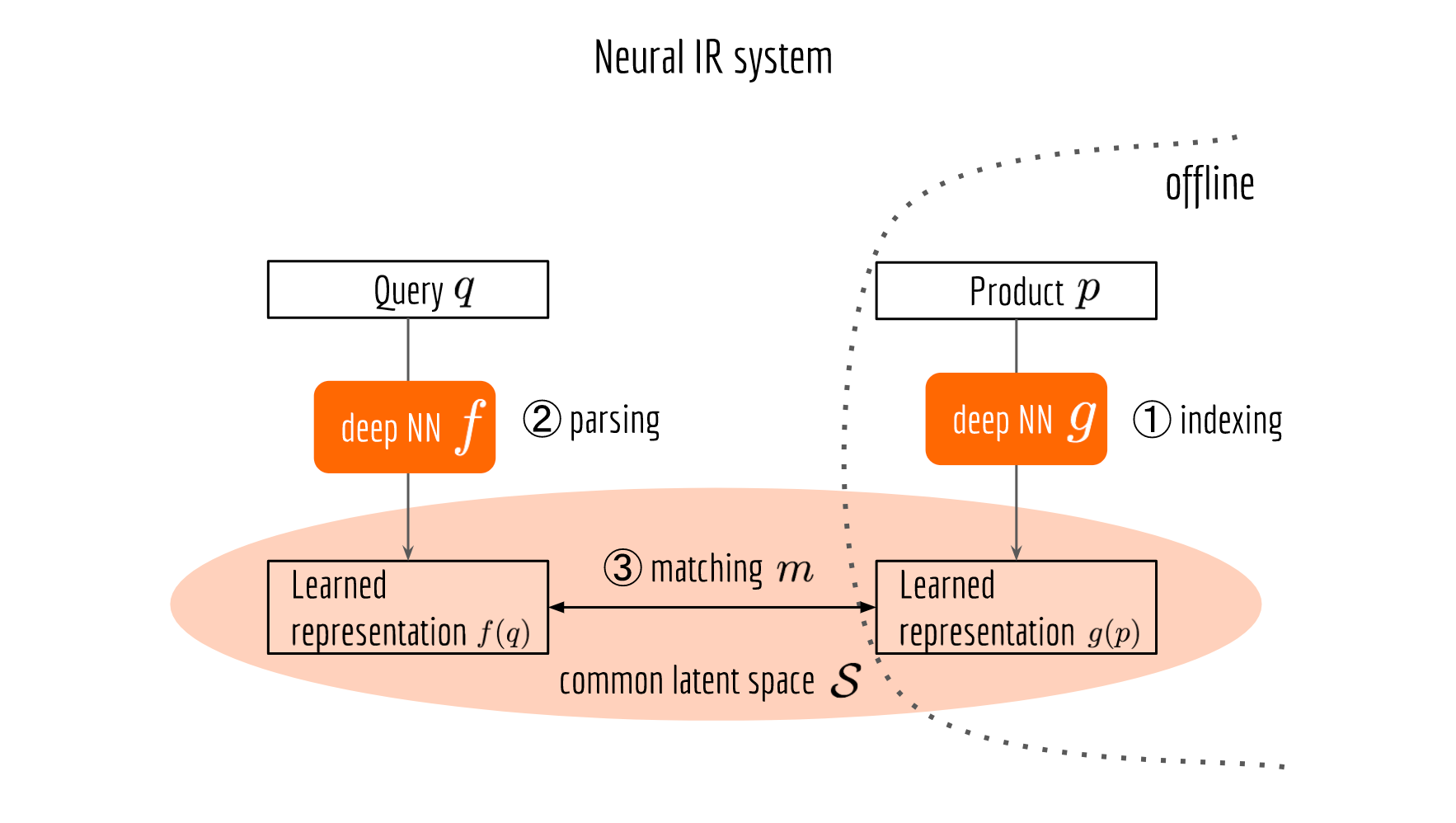
Symbolic vs. Neural Search System
Neural IR is a new concept emerging just recently. There are not so many off-the-shelf packages available. Plus, training a neural IR system requires quite some data. The next table summarizes the pros and cons of two systems.
Symbolic IR system Neural IR system Pros Efficient in query-time;
straightforward to implement;
results are interpretable;
many off-the-shelf packages.Automatic;
resilient to noise;
scale-out easily;
requires little domain knowledge.Cons Fragile;
Hard-coded knowledge;
high maintenance costs.Less efficient in query-time;
hard to add business rules;
requires a lot of data.
From the market perspective, there are two pain points of the current token/symbolic-based search:
- Increasing unsearchable content in enterprise IT & consumer markets that are not handled by the token/symbolic-based search. This includes images, videos, animations, audios, 3D model renderings, and meta data.
- Evolving needs have been shifted from count-based statistics to the cognitive/AI-driven insights, e.g. QA on enterprise wiki, media resources search, and meta-data intelligence.
Reading Comprehension in Search System
Having a search system with the reading comprehension ability can make the user experience smoother and more efficient, as all time-consuming tasks such as retrieving, inferring and summarizing are left to the computers. For impatient users who don’t have time to read text carefully, such system can be very useful
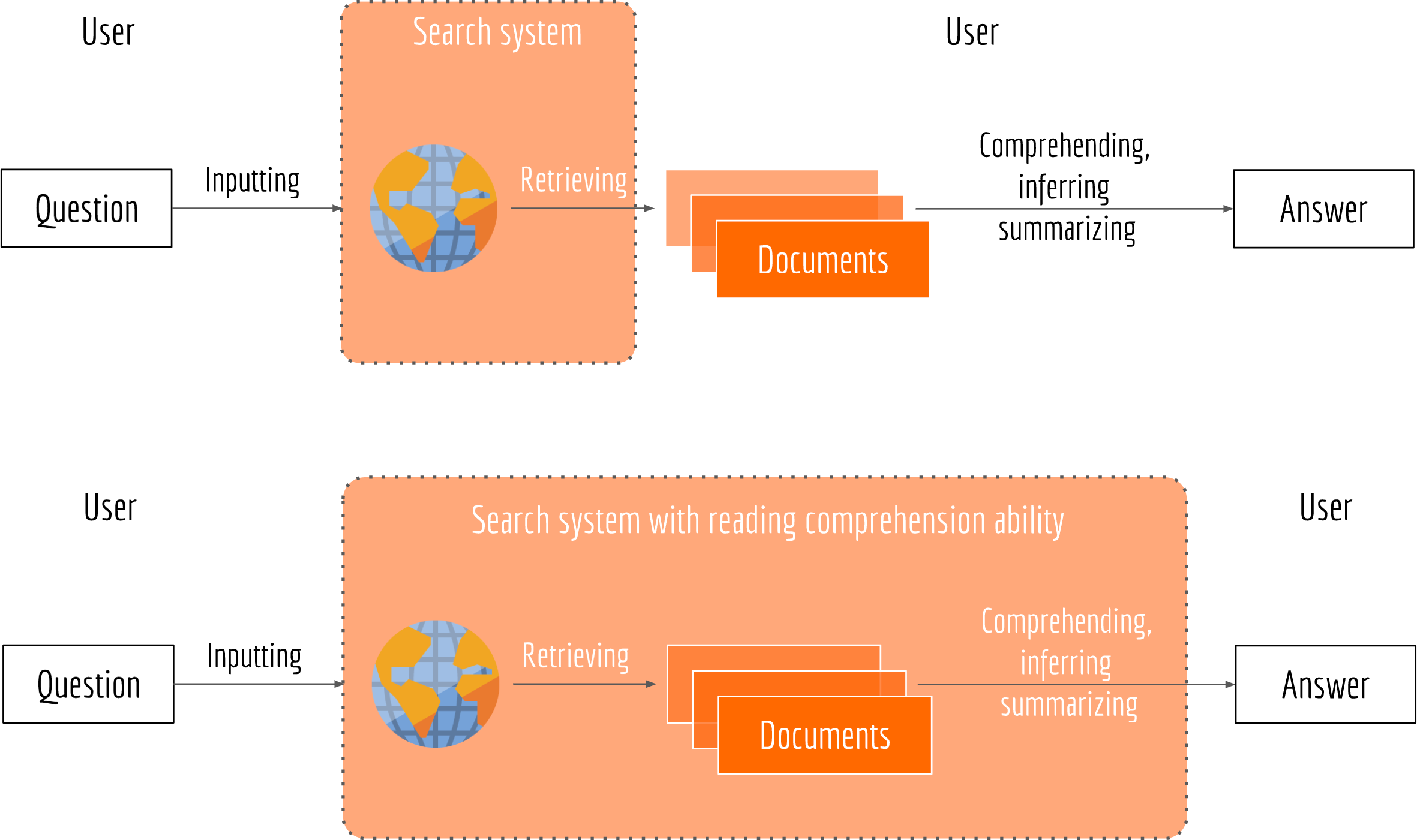
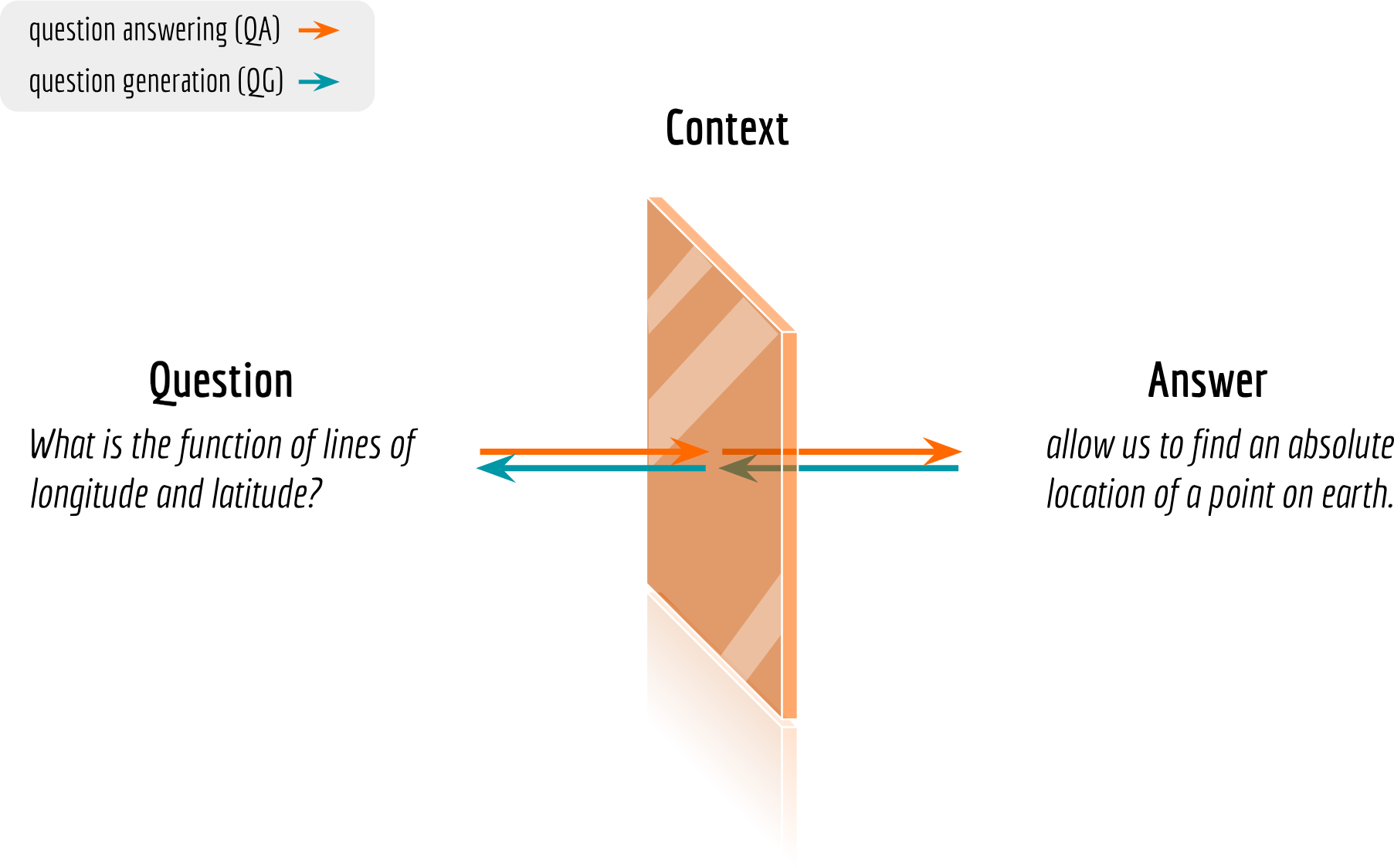
The Duality in Question Answering System
three modalities in the reading comprehension setting: question, answer and context. There are three modalities in the reading comprehension setting: question, answer and context. One can define two problems from different directions:
- Question Answering (QA): infer an answer given a question and the context;
- Question Generation (QG): infer a question given an answer and the context.
Careful readers may notice that there is some sort of cycle consistency between QA and QG: they are both defined as inferring one modality given the counterpart based on context.
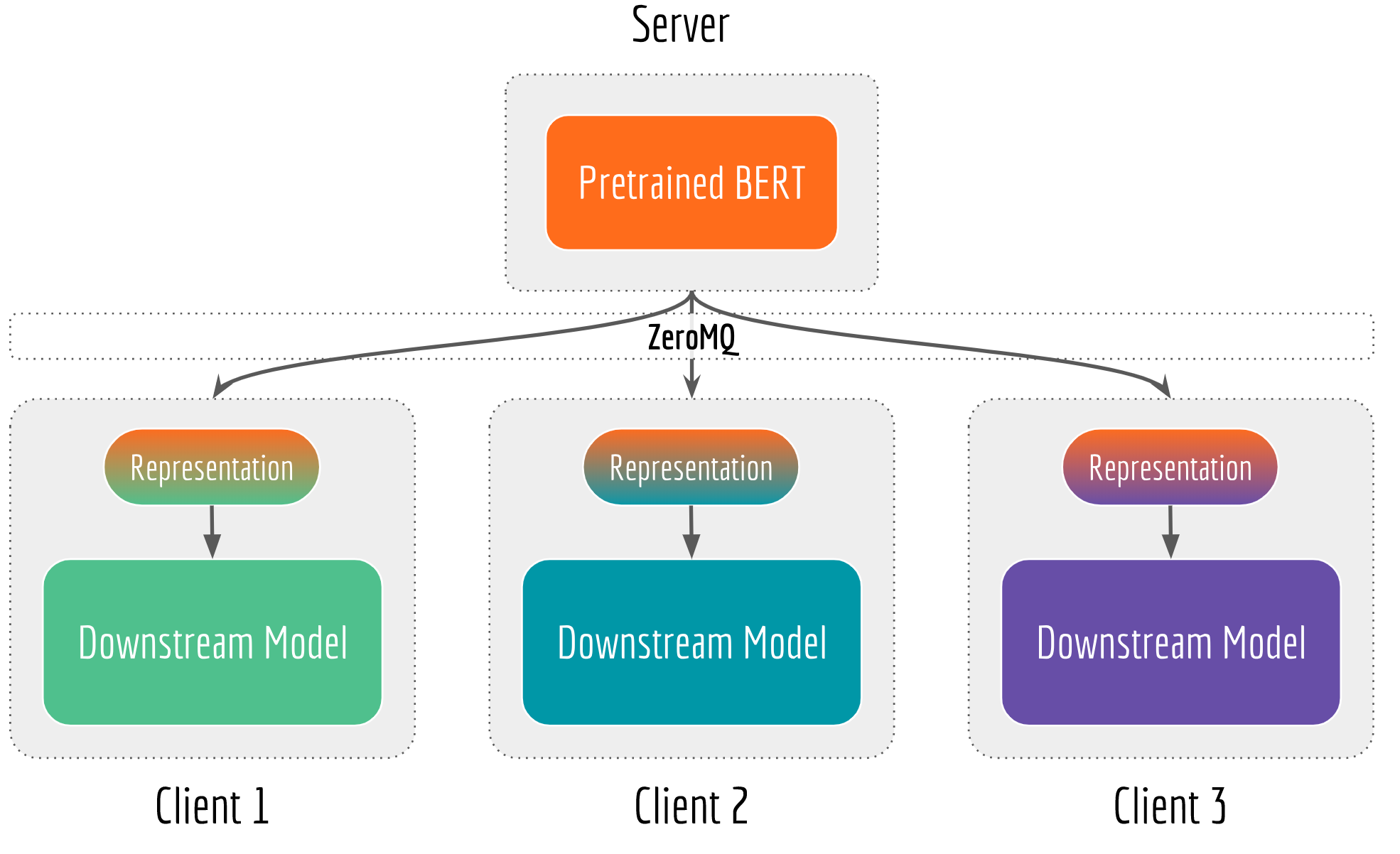
Sequence Encoding as a Service
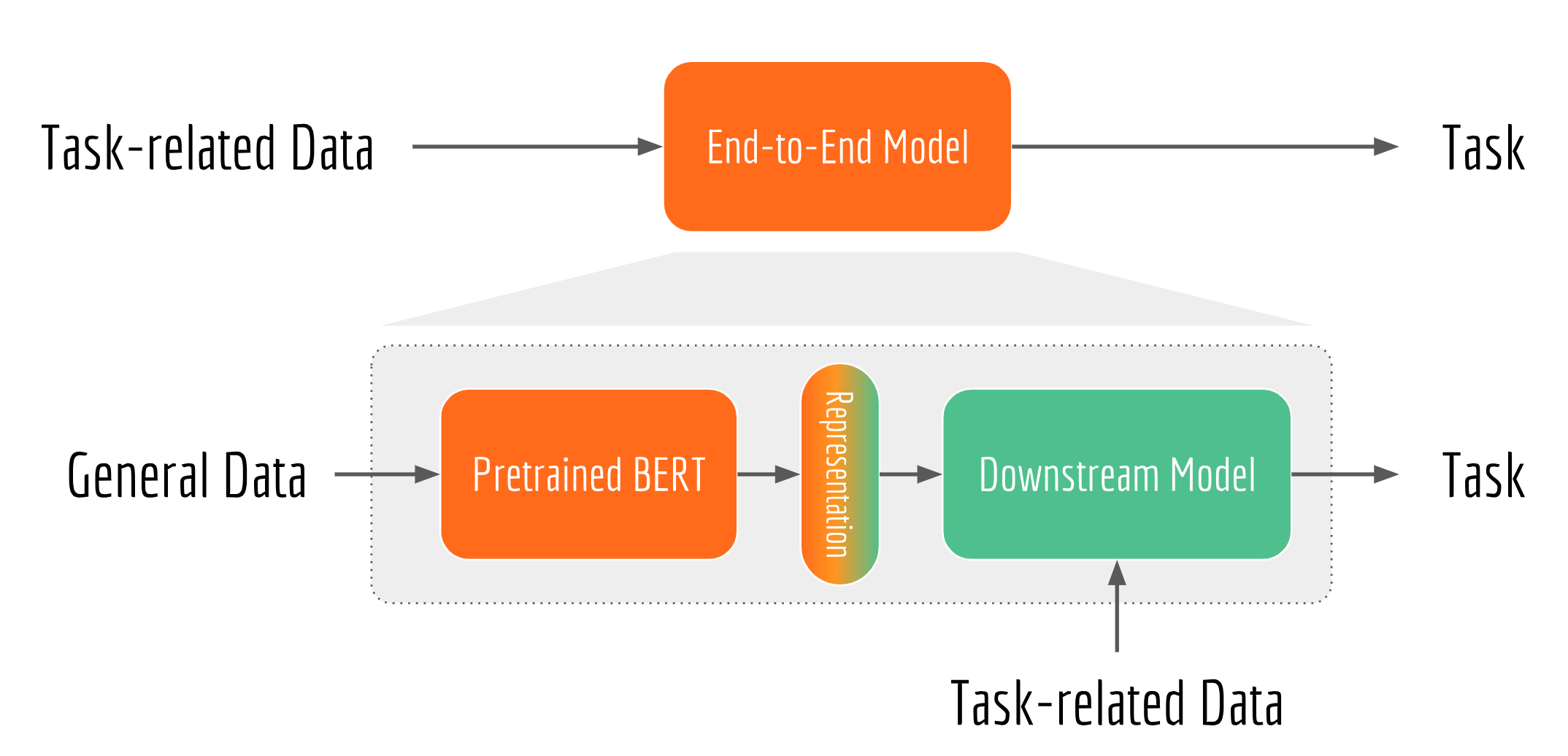
So if many NLP applications rely on semantic features, then why don’t we build a sentence encoding infrastructure that can serve multiple teams? This idea, despite how simple and straightforward, is not really practical until recently. Because many deep learning algorithms tailor the vector representation to a specific task or domain. Consequently, the representation from one application/team is not really reusable to other applications/teams. On contrary, BERT (as well as ELMo and ULMFit) decomposes an NLP task into task-independent pretraining and task-specific fine-tuning stages, where pretraining learns a model that is general enough and can be reused in many downstream tasks.
Bert-as-service Architecture
Decoupling also clarifies the C/S role. When the feature extraction becomes the bottleneck, then scale up the GPU server. When the downstream network is the bottleneck, then optimize the client by adding more CPU machines or doing quantization. When training data is too old or concept-drifted, then retrain the BERT and version-control the server, all downstream networks immediately enjoy the updated feature vectors. Finally, as all requests come to one place, your GPU server has less idle cycles and every penny is spent worthily.
Training, Indexing, and Querying in a Neural Search System
The first concept I’d like to introduce is the runtime. In a typical search system, there are two fundamental tasks: indexing and querying. Indexing is storing the documents, querying is searching the documents on a given query, pretty straightforward. In a neural search system, one may also face another task: training, where one fine-tunes the model according to the data distribution to achieve better search relevance.
Jina is “Tensorflow” for Search
I often use the analogy “Tensorflow” for search to explain what Jina is. Jina sits one layer above the universal deep learning framework (e.g., Tensorflow, Pytorch, Mindspore); it provides the infrastructure for building AI-powered search applications. So the next time you develop a multi-/cross-modalities search app (question answering, image/video/audio search), Jina will be your go-to “programming language”. It helps you get the job done quickly and beautifully by providing you first-class support on AI models and rich cloud-native features.
Jina is Not an One-Liner
Jina follows a progressive way when doing abstraction. Unlike one-liners, Jina is shipped with multiple layers of abstractions, each layer targets a particular developer group. As a consequence, users can choose different levels of API to interact with Jina and accomplish the task. Designing and architecting Jina becomes finding what the essential complexity is, and then moving it around.
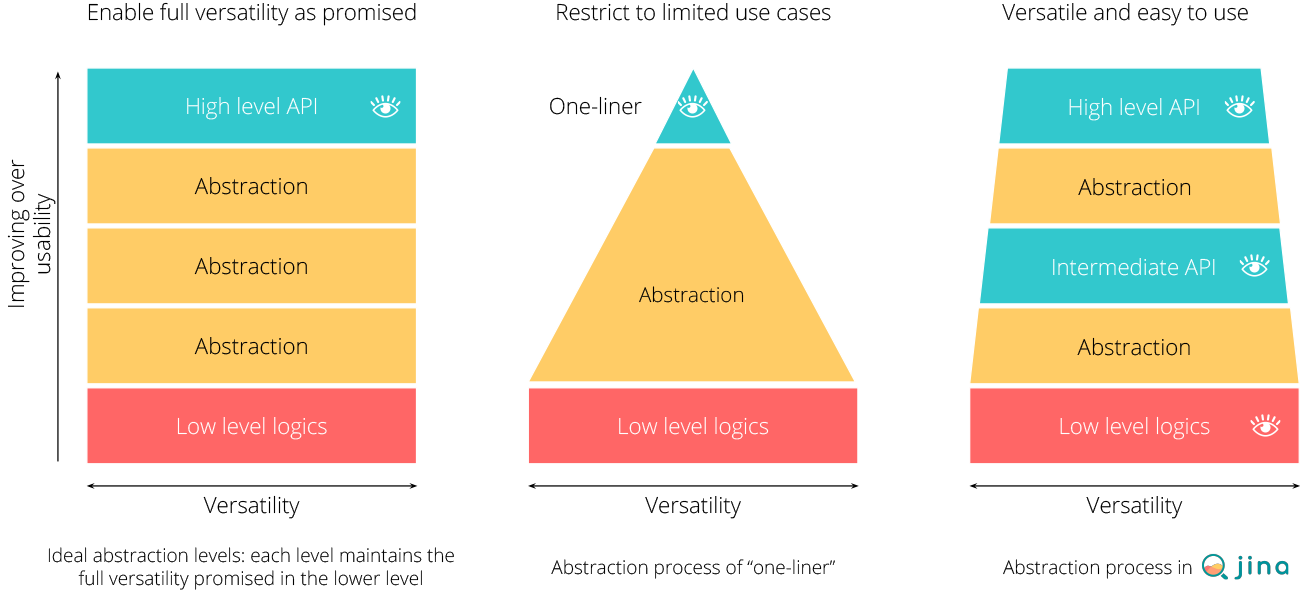
Implementing the Right Feature at the Right Layer
The biggest decision often is not about what this API layer does do, but instead what it doesn’t do.
Representation Learning
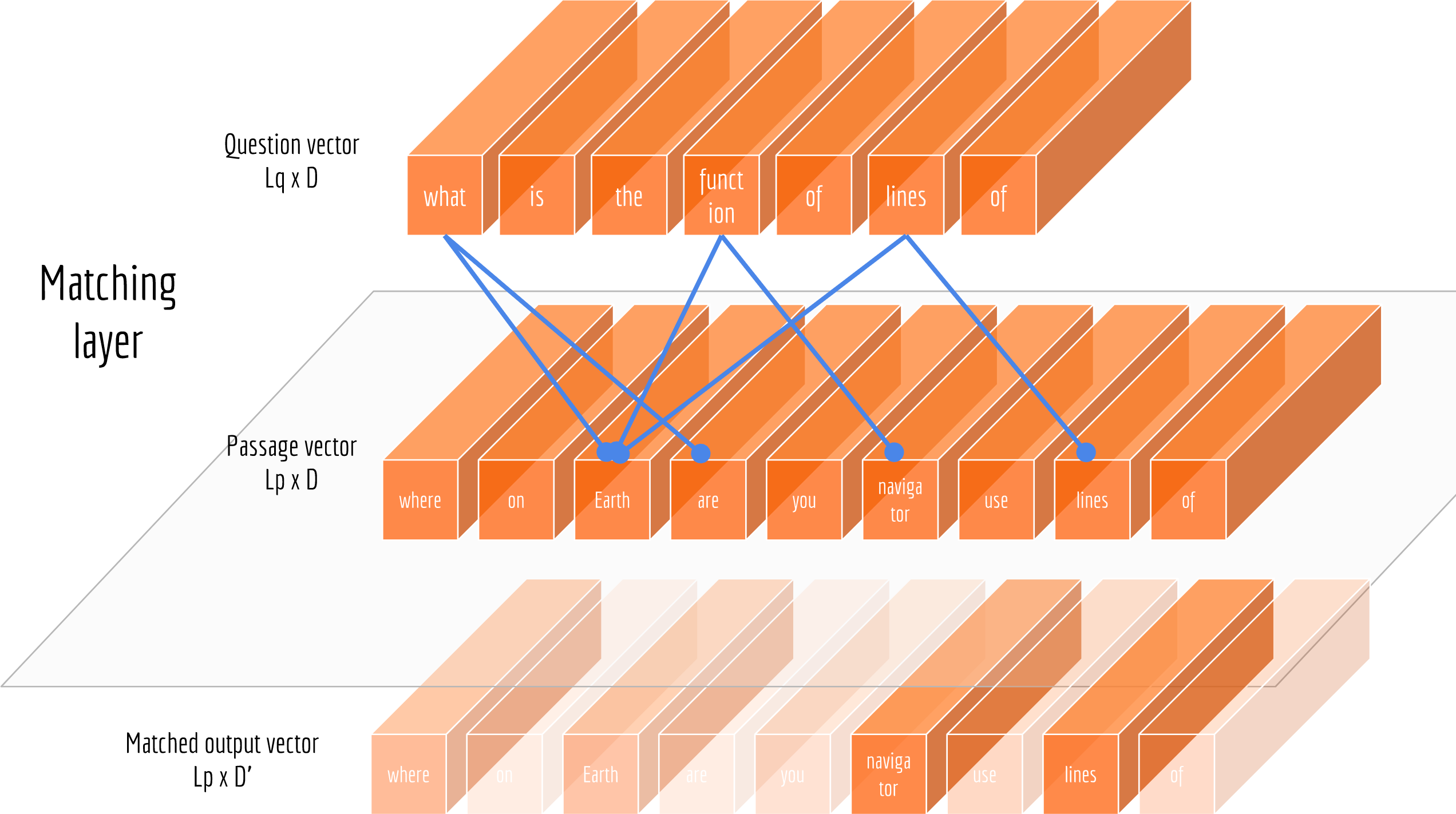
Matching Question and Passage Embeddings
Now that we have represented questions and passages into vectors, we need a way to exploit their correlation. Intuitively, not all words are equally useful for answering the question. Therefore, the sequence of passage vectors need to be weighted according to their relations to the question.
Dual Learning Paradigms in QA Search
Some very recent MRC works have also recognized the relationship between QA and QG and exploited it differently. They designed some sharing scheme in the learning paradigm to utilize the commonality among the tasks. For readers that are familiar with multi-task learning, it should be no surprise. Sharing weights or low-level representations enables the knowledge to be transferred from one task to another, resulting a model with better generalization ability.

Fast Sequence Embedding without LSTM/RNN
Also, don’t forget that sequence encoding is often just a low-level subtask of our ultimate goal (e.g. translation, question-answering). The upper layers are waiting for the encodes so that they can carry on more interesting tasks. Thus, it is not worth spending so much time on the encoding task itself.
All in all, we need our sequence encoding to be fast. A faster sequence encoder boosts the development cycle of our team, enabling us to find the optimal model by exploring more architectures and hyperparameters, which is crucial for bringing AI into production.
- Average Pooling and Max Pooling
- Hierarchical Pooling
- Attentive Pooling
- Final Touch
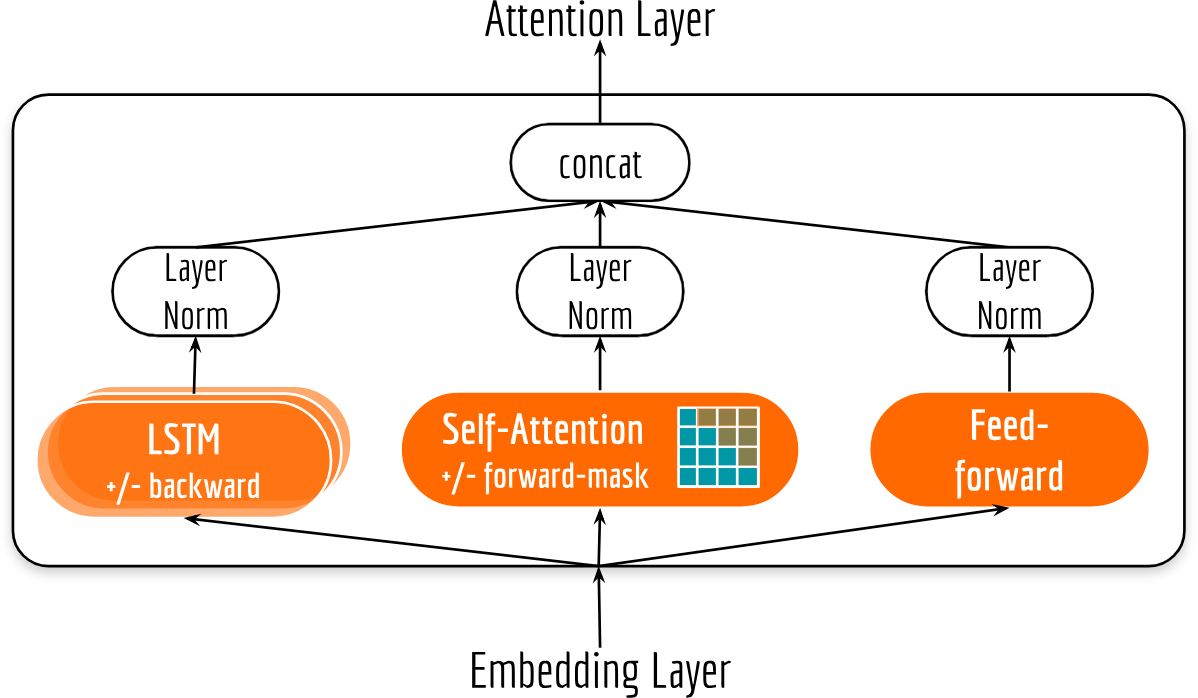
Compound Encoders for Sequence Embeddings
Each encoder consists of the following basic building blocks: an element-wise fully connected feed-forward block, stacked LSTMs and a self-attention block. The final output of an encoder is a concatenation of the outputs of all blocks.
Representation Learning in 2-Step: Pre-training and Fine-tuning
- Pretraining learns from plain text data that is publicly available on the web, with the goal of capturing the general grammar and contextual information of a language.
- Fine-tuning learns from a specific task (e.g. sentiment analysis, machine translation, reading comprehension) or data from a particular domain (e.g. legal documents).
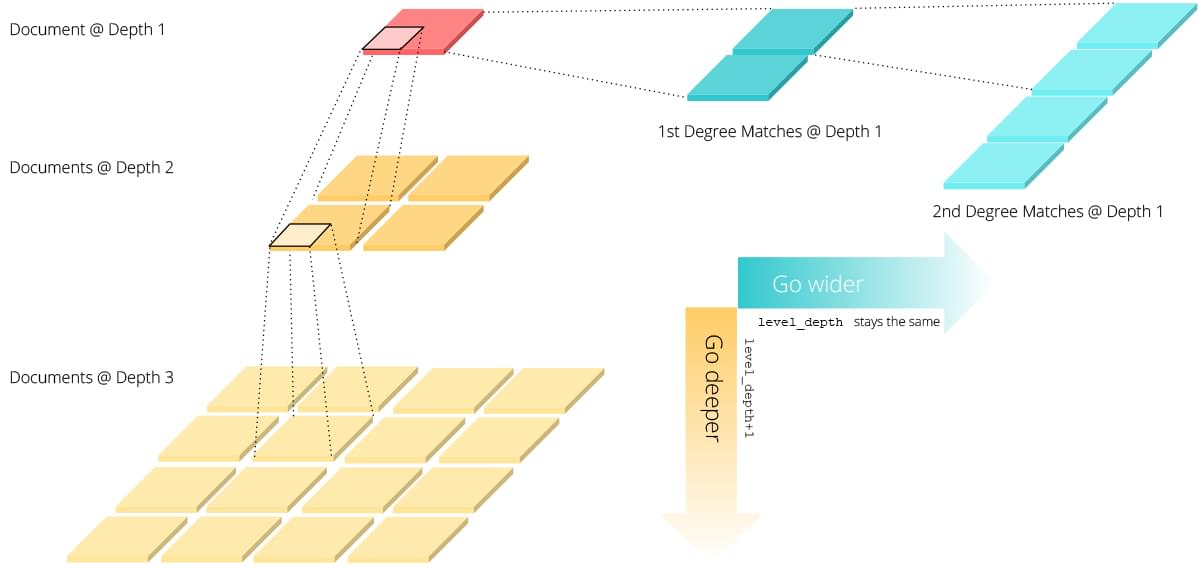
Recursive Document Representation
Documentnow has a recursive structure with arbitrary width and depth instead of a trivial bi-level structure. Roughly speaking,chunkscan have the next levelchunksand the same levelmatches; and so doesmatches. This could go on and on.
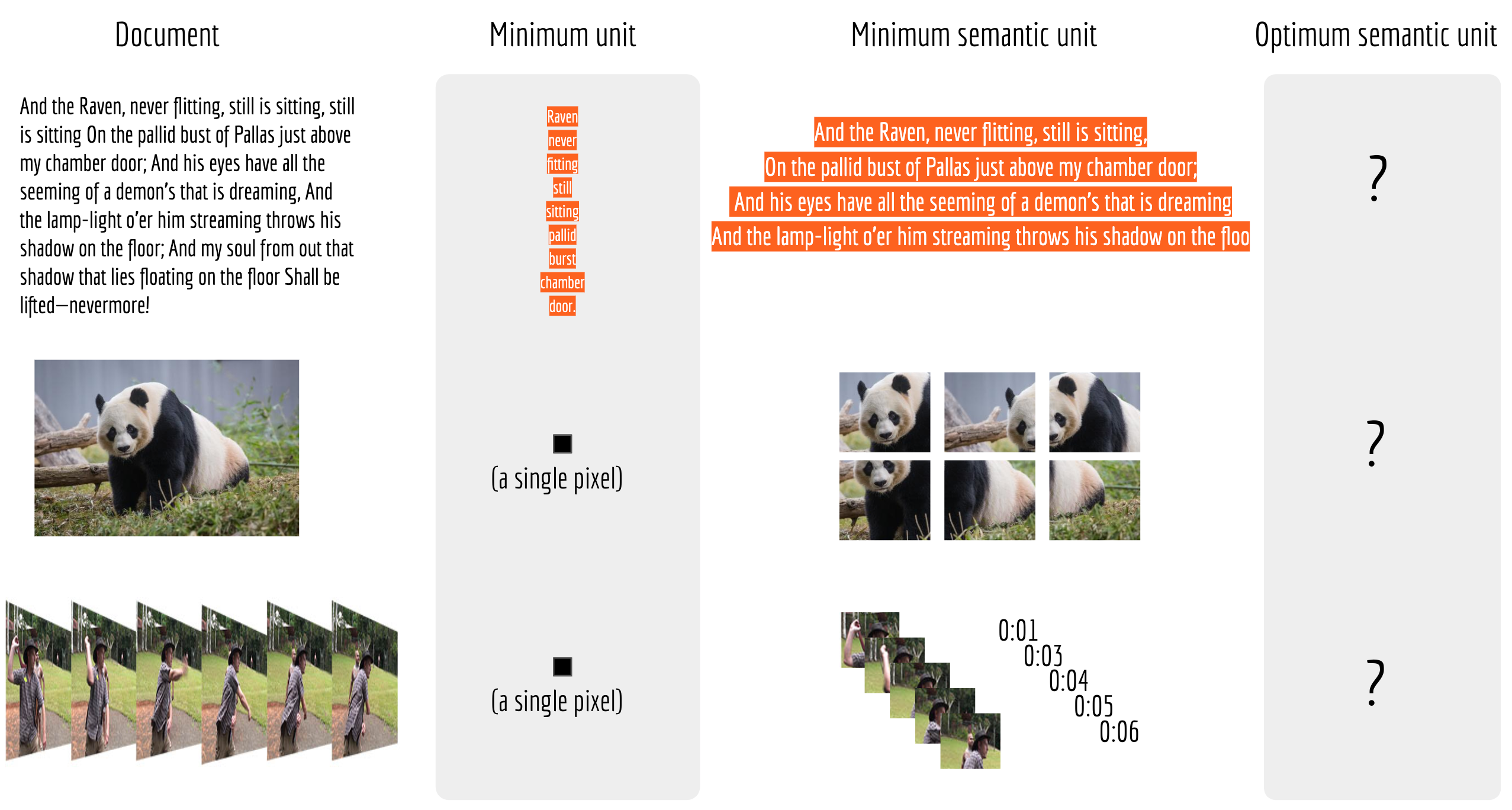
Comparable Semantic Units
A good neural search is only possible when document and query are comparable semantic units.
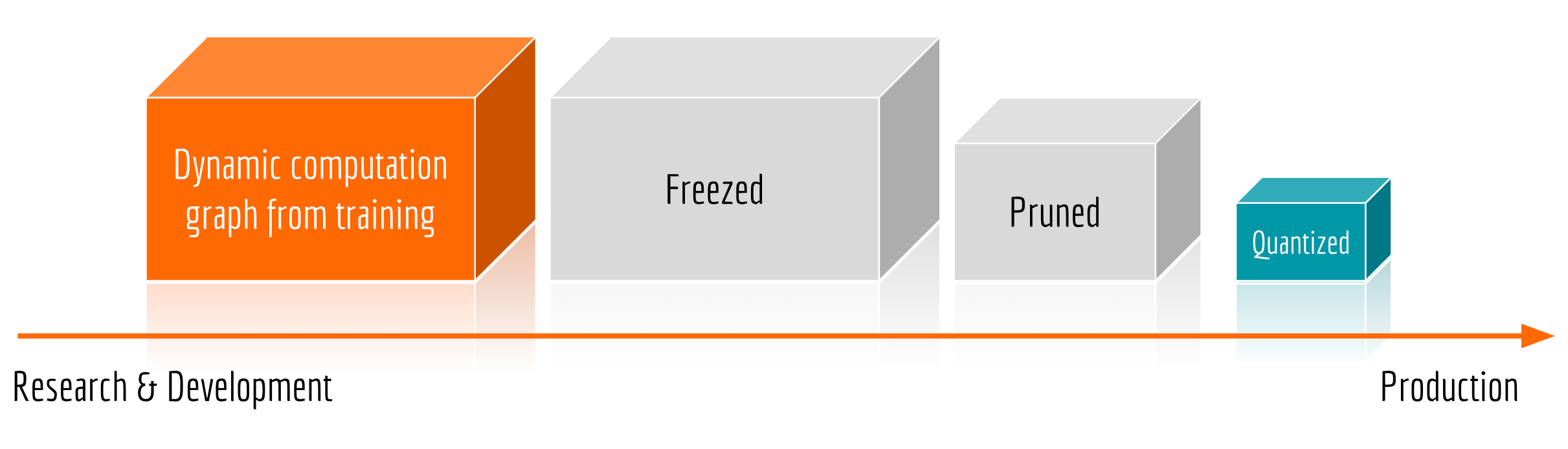
Production Ready
Serving with Fast Inference Speed
Specifically, freezing substitutes all variables by constants, i.e. from
tf.Variabletotf.Constant. Pruning removes all unnecessary nodes and edges from the graph. Quantizing replaces all parameters by their lower precision counterparts, e.g. fromtf.float32totf.float16or eventf.uint8. Currently, most quantization methods are implemented for mobile devices and therefore one may not observe significant speedup on X86 architectures.
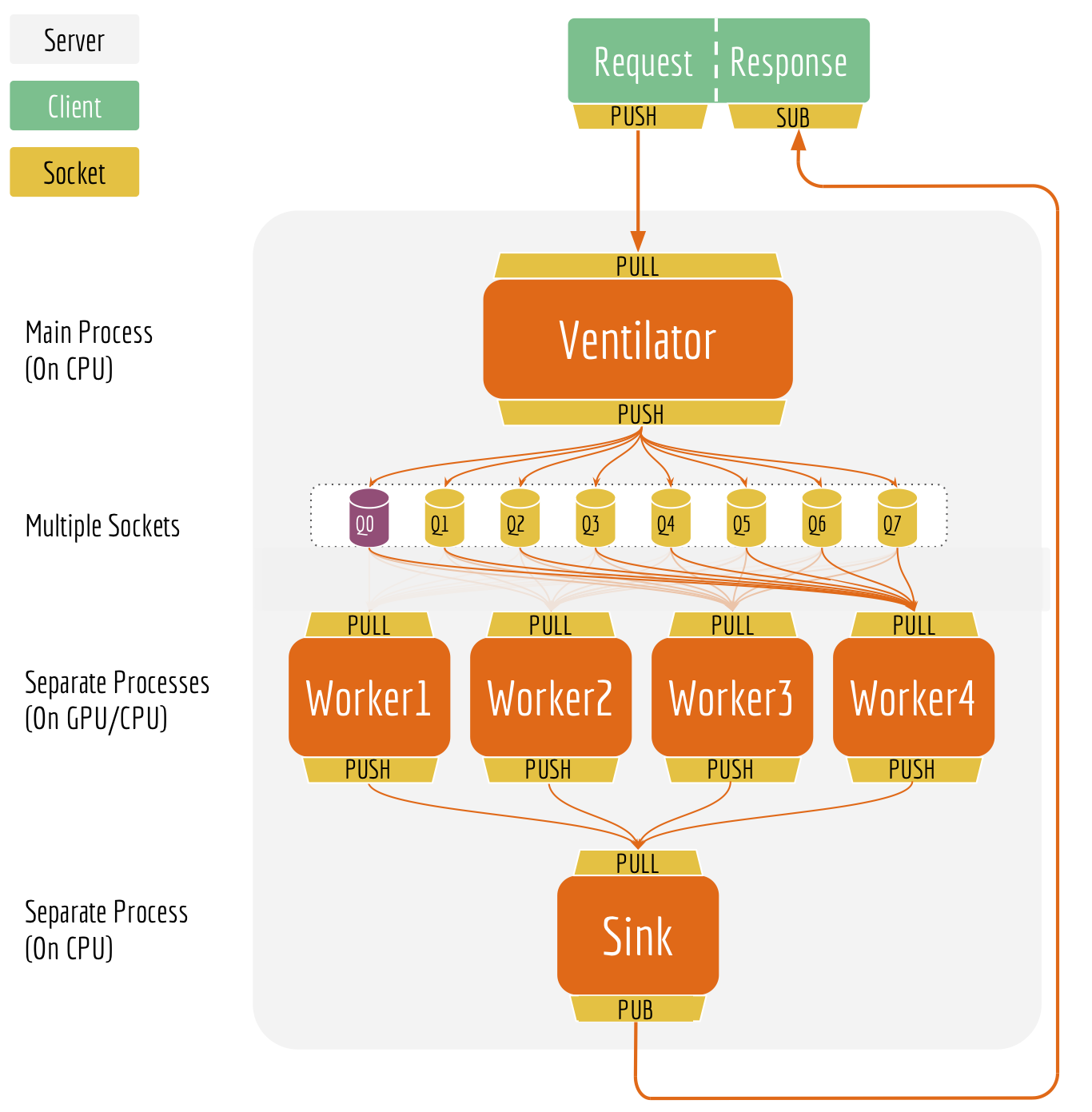
Serving with High Scalability
As the second example, consider a client is sending 10K sentences at every 10ms. The server parallelizes the work into sub-tasks and assigns them to multiple GPU workers. Then another client joins in, sending one sentence per second. Instinctively, this small-batch-client should get the result instantly. Unfortunately, as all GPU workers are busy computing for and receiving from the first client, the second client will never get a time slot until the server finishes 100 batches (each with 10K sentences) from the first client.
Sustainability of Model
From time to time, one frequent question I was often asked by the community is: “Han, can you support model X and make it X-as-a-service?”
This makes me wonder if bert-as-service has a sustainable architecture, in which rapidly changing requirements can be met by constantly adding new models to it, not modifying (and breaking) old ones.
Reproducibility of Model
Let’s first look at what an algorithm usually requires to run/reuse:
- dependencies: packages or libraries required to run the algorithm, e.g.
ffmpeg,libcuda,tensorflow;- codes: the implementation of the logic, can be written in Python, C, Java, Scala with the help of Tensorflow, Pytorch, etc;
- a small config file: the arguments abstracted from the logic for better flexibility during training and inference. For example,
batch_size,index_strategy, andmodel_path;- big data files: the serialization of the model structure the learned parameters, e.g. a pretrained VGG/BERT model.
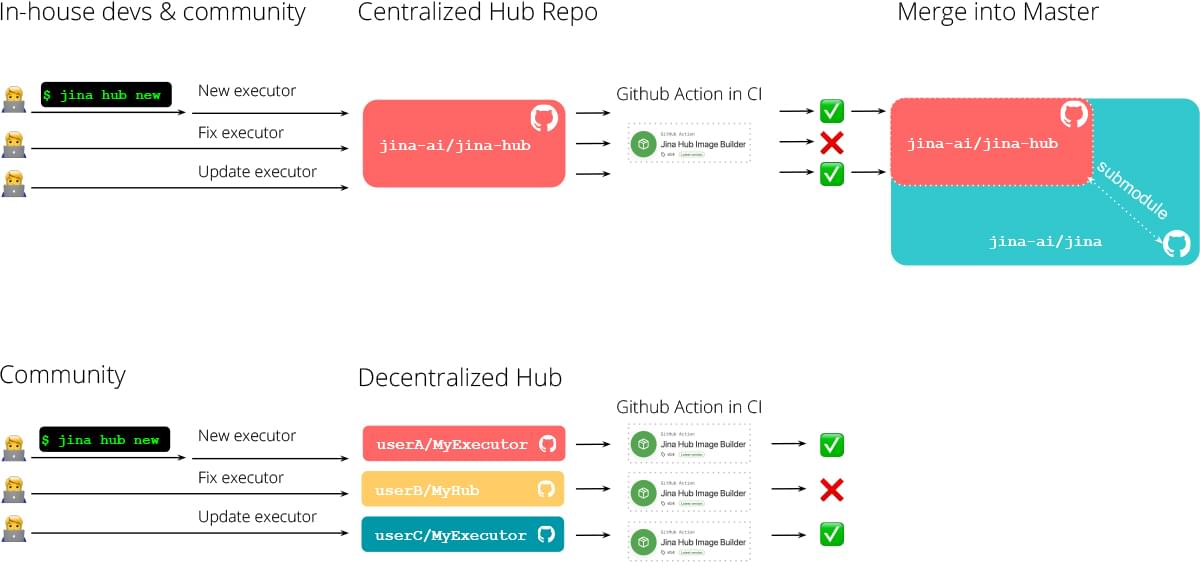
Centralized vs. Decentralized Hub
One can also maintain executors in its own (private) repository by simply adding this Github action to the CI/CD workflow. In other words, we provide both centralized and decentralized ways to use Hub.