






New Features in Jina v0.5 You Should Know About
Background
Today we are excited to release Jina v0.5.0. Jina is an easier way for enterprises and developers to build neural search in the cloud. The new version is a great accomplishment made by our engineers and the open-source community: it contains 700 new commits covering 400 files and 7000 lines of code since v0.4.0. The new release also introduces breaking changes and advanced features such as recursive document representation, query language driver, and hub rebuild. In this post, I will go through some of the highlight features we have made on v0.5.0 and explain the rationale behind them.
Table of Contents
Recursive Document Representation
In Jina, Document is anything you want to search for. Engineering-wise, Document is a first-class structure defined by Protobuf. On the high-level, the Flow ingests Document for indexing, searching, training and evaluating; on the low-level, the driver reads and modifies Document or passes it to another driver. Besides the general properties such as id, length, weight, what makes Document interesting is that each Document contains a list of Chunk. The Chunk is a small semantic unit of a Document, like a sentence or a 64x64 pixel image patch. Most of the algorithms in Jina works on the Chunk level, the results are aggregated back to ScoredResult (which wraps a Document structure) before returning to the user. Before v0.4.1, Chunk and ScoredResult have their own Protobuf specification, though they share many common attributes.
In v0.5.0, we unify the Protobuf definition of Document, Chunk and ScoredResult. This dramatically simplifies the overall interface.
| Before | v0.5.0 | ||||
|---|---|---|---|---|---|
|
|
One immediate consequence is that Document now has a recursive structure with arbitrary width and depth instead of a trivial bi-level structure. Roughly speaking, chunks can have the next level chunks and the same level matches; and so does matches. This could go on and on. The following figure illustrates this structure.

This recursive structure allows Document to represent many real-world objects much comfortable than before. For example, in NLP a long document is composed of semantic chapters; each chapter consists of multiple paragraphs, which can be further segmented into sentences. In CV, a video is composed of one or more scenes, including one or more shots (i.e. a sequence of frames taken by a single camera over a continuous period time). Each shot includes one or more frames. Such hierarchical structures can be very well represented with this new Protobuf definition.
Recursive Drivers Work as Convolution/Deconvolution
With a low-level change like that, one may expect massive work on refactoring the high-level implementation. In fact, the refactoring work is mostly concentrated on the Driver layer, leaving Pea, Pod, Flow untouched. I talked about the importance of having layered APIs for progressive abstraction in large framework design in my earlier post. Feel free to read that post if you are interested.
Erasing the difference between Document and Chunk does now make Executor completely “Protobuf-agnostic”, allowing one to implement Executor more consistently. For instance, our previous ChunkSpecificExecutor, DocSpecificExecutor can now be unified into one.
What is really interesting is the way that Driver works now. In v0.5.0, we add two essential attributes depth_range and traverse_on to the drivers, which allows them to follow the Document structure and work recursively. By default, all drivers work on the root level (i.e., level_depth=0) only. To enable the recursion on deeper/wider levels, one can simply specify depth_range. In the following example, BaseKVIndexer indexes all Document from level-0 and 1. One can also limit the operation to a specific level by setting depth_range: [k, k].
1 | !BaseKVIndexer |
Recursive segmentation becomes extremely simple. Say we want to segment a long document while keeping its hierarchical structure, the implementation could look like the following:
LongTextSegmenter | myseg.yml | ||||
|---|---|---|---|---|---|
|
|
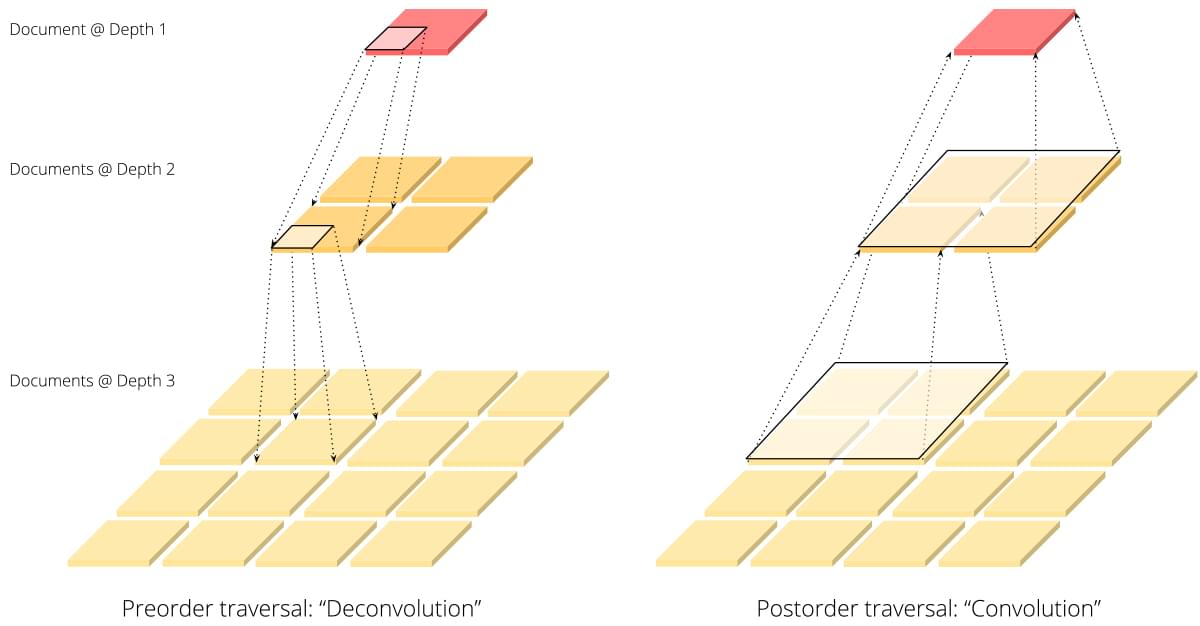
The recursion can go both directions: deeper or shallower, depending on the preorder or postorder traversal) that the driver follows. In the segmenting example above, SegmentDriver follows the preorder traversal: create segments first and then deep diving into them. On the contrary, BaseRankDriver works in another direction: we first have to collect matching scores at deeper level and then aggregate this info back to the root level. Readers who have a basic AI background may quickly realize this is quite similar to convolution and deconvolution operations in deep neural networks.
Hello-World after Refactoring
To see how effective this structure is, let’s make a side-by-side comparison on the Flow YAML specification behind jina hello world. From 23 lines to 11 lines! Not bad at all!
v0.4.0 | v0.5.0 | ||||
|---|---|---|---|---|---|
|
|
New Query Language Driver
In v0.5.0, we introduce a new set of Driver called Query Language Driver. It is designed for filtering the content of the request based on the condition defined in the YAML or the payload, so that the executor only works on the filtered request. Query language driver can also be used to route requests into different sub-flows based on the condition. In the example below, by equipping FilterQL driver to IndexRequest, Mode2Encoder will only work on Document whose modality = mode2 and leave others untouched.
1 | !Mode2Encoder |
Besides setting the attributes in YAML, one can also override the attributes of a Query Language Driver by setting request.queryset in the Protobuf message. For example,
1 | from jina.flow import Flow |
The following query language drivers have been implemented in v0.5.0:
| Query Language Driver | Description | Common Name in other query language |
|---|---|---|
FilterQL | filter Document by its attributes | filter/where |
SelectQL, SelectReqQL, ExcludeQL, ExcludeReqQL | select attributes to include in the results | select/exclude |
SliceQL | take a part of the list of Document | limit/take/slicing |
SortQL | sort list of Document by some attribute | sort/order_by |
ReverseQL | reverse the list of collections | reverse |
Retrospect: Query Language From Scratch
It is interesting to take a retrospect of how we end up here. Essentially, we need an in-memory ORM/SQL that supports expressions and clauses and allows users to compose advance queries. Though Python has built-in advanced comprehensions covering a big chunk of SQL already, it is not easy to define Python expressions in YAML or JSON. In the early version of Jina, I have tried to leverage eval() and compile() in Driver to parse arbitrary Python expression. It certainly accomplished the task itself but leaving a big security risk to the whole stack. It is not a fair exchange.
We also reviewed several open-source solutions that implement similar functionality, however, each has some limitation:
- Protobuf
FieldMask: can not select sub-fields in therepeatedfields; - QuerySet in Django: add extra dependency
Django, overkill; - pythonql: can not parse query language from YAML/JSON;
- lookupy: do not support nested structure in a list, not actively maintained;
- py-enumerable: designed to be LINQ in Python, can not parse query language from YAML/JSON;
- pyflwor: a customized model view for the data, not actively maintained and BSD license;
- django-pb-model: need to maintain two views (Protobuf and Django) of every
Message/Requestand frequently converting between them.
In the end, we decided to implement the query language from scratch. There are two ways to implement it:
- Implement a single all-mighty
QueryLangDriver, which handles complex language parsing internally. - Implement each query operator as an orthogonal
Driver. The complex query language is realized by chaining small independent drivers together.
While Option (1) looks like a cleaner solution, implementing a new query language is non-trivial. We likely have to create a new DSL and its parser. Frankly, nobody likes DSL. Option (2) is much easier to implement and to test. However, some complex syntax may not be realized, as the query language built in this way is always fluent-style.
Jina v0.5.0 goes for the second option. We also leave an interface for the first option, see BaseQueryLangDriver.
Hub as a Git Submodule
In v0.5.0 all concrete Executor classes are moved to a separate repository jina-ai/jina-hub. The jina-hub repository is then used as a git submodule in jina repository under the folder hub/. Only abstract executors such as BaseExecutor are maintained in the jina repository under the folder executors/. We also clarify the file structure of a customized executor. Besides the Python code, the bundle should include manifest.yml, Dockerfile, tests, and README.md. Users can simply type jina hub new in the console to create a new executor from the template. The following figure illustrates this idea.

To list all executors, one can use jina check. As before, Hub executors can be used in the executor YAML,
1 | !BigTransferEncoder |
or in Python,
1 | from jina.hub.encoders.image.BigTransferEncoder import BigTransferEncoder |
One can also build the executor into a Docker image via:
1 | jina hub build . |
and then use the image directly in Flow API
1 | f = Flow().add(uses='jinahub/pod.encoder.BigTransferEncoder:0.0.2') |
In v0.5.0, unit test is required for all Hub executors. To enforce this rule, we add pytest into the bundle template and Dockerfile. The developer needs to implement the test case based on the given boilerplate. This ensures that every built image can be run out of the box. We wrap the Hub building logic into a Github action and publish it in Github Marketplace, allowing people to use it in their own CI/CD workflows.
Decoupling Hub from the Jina main repository is crucial and must be done now. With the increasing size of the project, the border between the core and hub becomes very fuzzy to the community. In the last two months, we found that nearly all executors are committed to jina/executors. However, customized executors often require extra dependencies and specific running environment that are not available locally, which poses the hardship of testing them in a single run. Before v0.5.0, not all executors in jina/executors are well tested, and the code quality varies greatly. This refactoring sets the Jina Hub back on track and helps our engineers and community to scale better as the project grows.
Centralized vs. Decentralized Jina Hub
Note that, committing to jina-ai/jina-hub repository is not the only way to contribute or use the Hub. One can also maintain executors in its own (private) repository by simply adding this Github action to the CI/CD workflow. In other words, we provide both centralized and decentralized ways to use Hub. The following figure illustrates these two procedures.

Summary
This post highlighted the three major updates in v0.5.0. Besides that, there are hundreds of patches about improving performance, scalability, and easy-to-use. While the project’s growth has introduced challenges, we feel very fortunate to have the open-source community on our side and keep the momentum going strong on the development of Jina. The number of contributors to Jina has increased to 49 by today. If you want to know more about our engineering roadmap and the rationale behind specific features, welcome to join our monthly Engineering All Hands in Public via Zoom or Youtube live stream. If you want to join us as full-time AI/back-end engineers, we are more than welcome, and please send your CV to [email protected]. Let’s build the next neural search ecosystem together!