






Benchmark a Decentralized Search System on 79 Past Releases
Jina is designed as a decentralized system from day one. Components are modularized as microservices, which we call Pea/Pod in Jina idioms. The data passing is done via ZeroMQ and gRPC. Comparing to the traditional deep learning frameworks that follow a monolith architecture, latency and overhead are something the community and we care about a lot.
From the first release v0.1 in May 2020 to 0.7.7 today, we have released 79 versions, including 2800+ new commits with 35K lines changes from 50+ contributors. How is the indexing and querying speed now comparing to May? Most importantly, how can we even benchmark fairly over different releases?
This post will explain our containerized benchmark environment and highlight those changes made in the last few months that significantly improve/degrade the performance.
Jina is an easier way for enterprises and developers to build cross- & multi-modal neural search systems on the cloud. You can use Jina to bootstrap a text/image/video/audio search system in minutes. Give it a try:

Table of Content
Containerized Benchmark
Benchmark Task
If you are a Jina user, then you must know jina hello-world: an one-liner that showcases the entire index and query workflows on Fashion-MNIST dataset. It indexes 60,000 images via an index flow. The vectorized data is stored into multiple shards. It then randomly samples test set as queries, ask Jina to retrieve relevant results. Below is Jina’s retrievals, where the left-most column is query image.

This one-liner demo has been shipped in every Jina releases since v0.1, with a consistent high-level task across versions regardless the changes of the low-level API. This is perfect for serving as our benchmark task. The code snippet below shows the sketch of the benchmark function:
1 | def benchmark(): |
Although Jina today provides many handy interfaces such as Flow.index_ndarray() and TimeContext, allowing you to write the same code more concisely; they are not necessarily available in the early versions. To maximize the compatibility, I use a very primitive style of Jina programming. I even put from jina import ... inside the try-except block, in case we don’t have those interfaces (or in a different module structure) in the early version. Readers should not take it as the best practice.
Reproducible Experiment via Containerization
So we want to run benchmark() by looping over all releases. Of course no one want to pip install one by one and mess up the local environment. We want to conduct each experiment in a clean and immutable environment, and make sure the whole set is reproducible.
I use the Docker image tagged with jinaai/jina:x.y.z published on every patch release. It is a self-contained image based on python:3.7.6-slim with all dependencies installed. My benchmark function (app.py) has to be running inside these containers to get an accurate result. Here is how the Dockerfile of a benchmark container looks like:
1 | ARG JINA_VER |
Note, ARG is put in front of FROM to make version number as a parameter, so that one can choose a specific version for benchmarking. I then wrap docker build and docker run with a simple Bash script, which lists all releases and loops over them:
1 | JINA_VERS=$(git ls-remote --tags https://github.com/jina-ai/jina.git "refs/tags/v*^{}" | cut -d'/' -f3 | cut -d'^' -f1 | cut -d'v' -f2 | sort -Vr) |
The figure below illustrates this procedure, where the results are aggregated to benchmark.json:
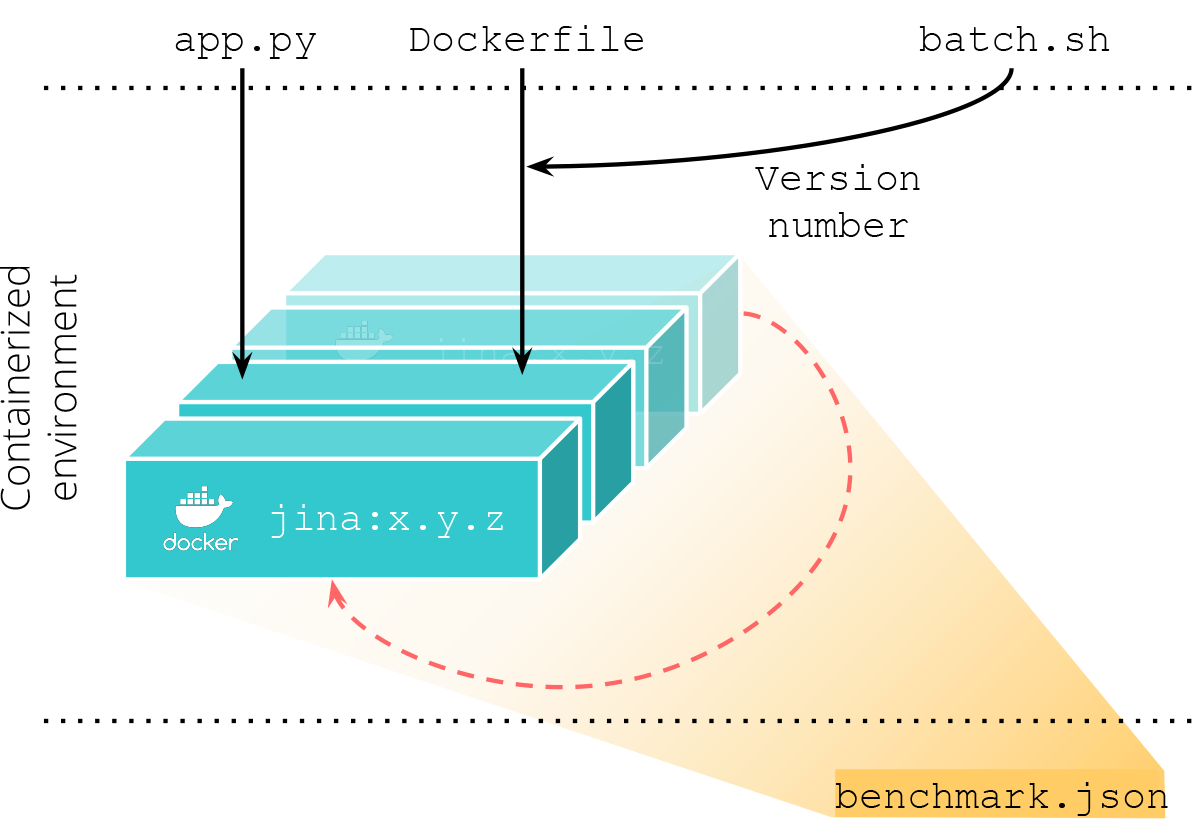
The source code behind the benchmark environment can be found here.
Quick Analysis on the Speed
I run the benchmark on a 6-Core i7 machine with 32GB memory, with parallelization and sharding set to 4. In the end, the earliest version I can benchmark is v0.0.8. That was on Apr. 23, 2020, one week before first release.
Index Speed
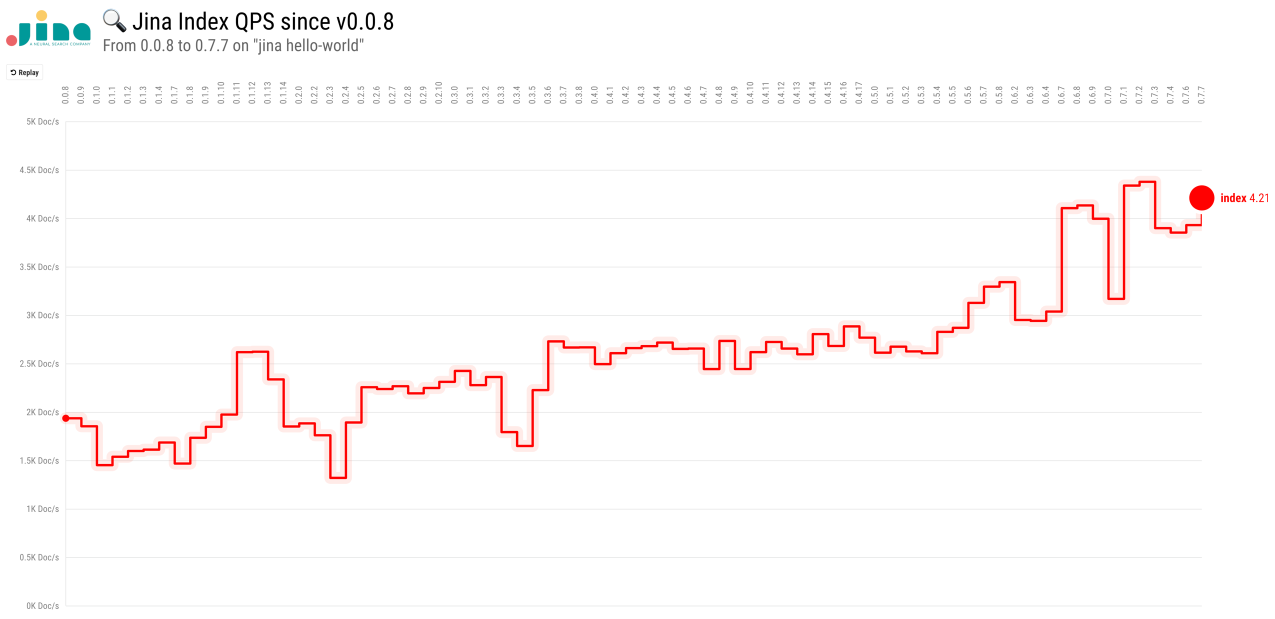
- The index speed has increased from 2000 docs/s to around 4000 docs/s over last few months.
- The
hello-worldindexing time for 60,000 docs is reduced from 32 seconds at0.0.8to 14 seconds at0.7.7. - Besides continuous refactoring, the major improvements come from:
- Introducing
zmqstream& async IO around0.3 - Unifying
Documentstructure andChunkstructure into one representation around0.5 - Removing
gzipcompression onDocumentand usingmemmapforKVIndexer&NumpyIndexeraround0.6 - Optimizing ZeroMQ binary protocol and introducing LazyRequest around 0.7
- Introducing
Query Speed
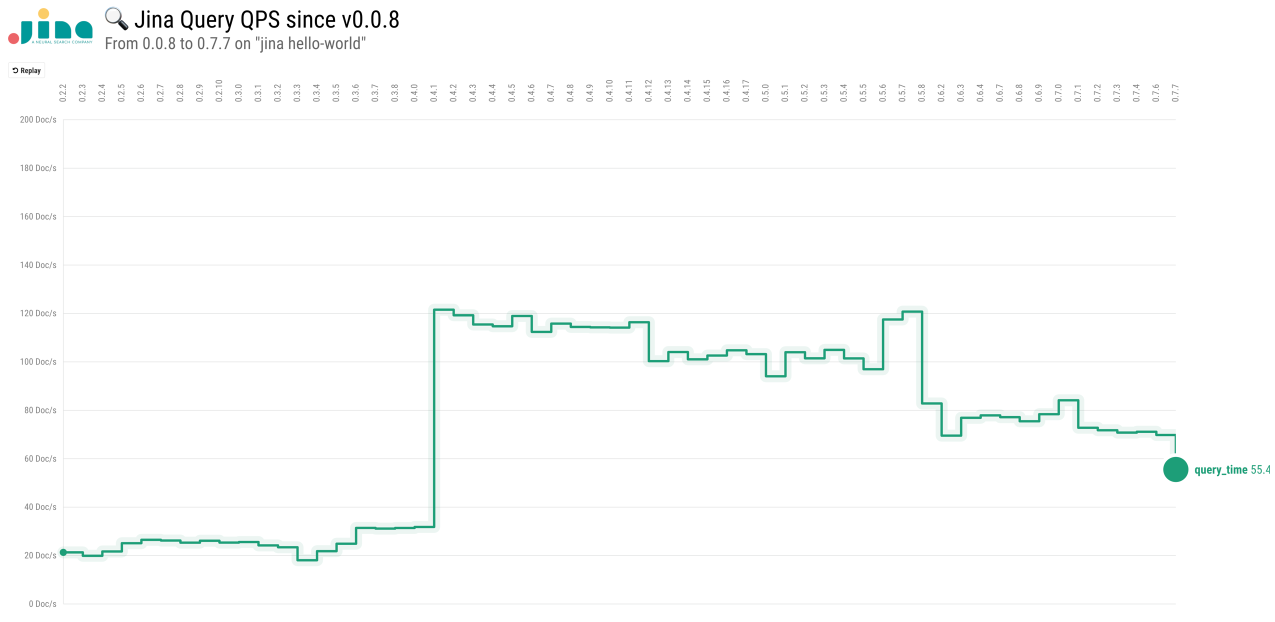
- The query speed has increased from 20 docs/s to around 70 docs/s over last few months.
- The major improvement around
0.4is due to unifyingDocumentstructure andChunkstructure. - The major setback around
0.6is due to the use ofmemmapforKVIndexer&NumpyIndexer. The search shifts away from in-memory search to on-disk search. - The slowly degraded query speed from
0.4to0.7could be due to the refactoring onExecutorandDriver, from then we have madeExecutorProtobuf-agnostic and algorithm-focus. Moreover, we have decoupled many huge all-in-oneDriverinto small pieces and then use them in a chain-style.QueryLangDriverintroduced in0.5is a good example. Though this effort is a sensible design decision and clarifies code structures, it may add extra dispatch overheads. - Need to keep an eye on the query speed in the future releases. More comprehensive analysis on the overhead is required. Avoid unnecessary work at the query time.
Summary
Like traveling with a time machine, it is fun to look back on what we had back in May. Interestingly, the architecture and high-level user experience are consistent enough to benchmark all history versions. Four things made this benchmark possible:
- The
hello-worlddemo defines a high-level task that is fixed across all releases. - Along with PyPI package on each release, we publish a Docker images with dependencies included, providing an immutable “playback” environment.
- Jina's multi-abstraction-layer design separates its high-level API from the intermediate and low-level API, allowing search developers to be agnostic on the lower-level changes.
- Last but not least, high code quality and robust DevOps & CICD infra from day one.
If you’d like to share some experiences and thoughts on latency issues, welcome to join our monthly Engineering All Hands via Zoom or Youtube live stream. If you like Jina and want to join us as a full-time AI / Backend / Frontend developer, please submit your CV to our job portal. Let’s build the next neural search ecosystem together!